2022.01.06 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE)
딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE)
2022.01.05 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (2 - Attention) 딥러닝 TA 모델 - BERT (2 - Attention) 2021.11.21 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (1 - 기..
shyu0522.tistory.com
에서 이어집니다.
지난 시간에 언어 학습을 위한 단어책(vocab.list)를 만드는 과정(data_preprocess)에 대해서 알아보았다.
data_preprocess과정은 사실 google git에 올라와있는 자료는 아니기에, sk academy의 내용을 약간 추가하여 알아보았다.
이번 시간에는, 실제 단어책을 가지고, 언어를 배우기 위한 문제집을 만드는 과정을 가져보겠다. (create_pretraining_data)
해당 소스는, https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=164
소스에 의거하여 작성되었으며, 해당 소스는,
https://github.com/google-research/bert/blob/master/create_pretraining_data.py
에 의거한다.

실제로 data_preprocess를 통해 생성된, 단어책과, (vocab.txt)
굳이 비유하자면, 실생활 문장을 이용한 한국어 배우기! 문제집을 만들기 위한, '실생활 문장' (Target Text)
Data가 필요하다.
변수명 'input_file'이 실제 Target Text가 된다.
가장 표면적인 부분부터 보면,
1) FullTokenizer
2) create_training_instances
3) write_instance_to_example_files
로 진행된다. 하나씩 알아보자.
(내가 올려놓을 git source는, 모든 메소드를 풀어서, 쥬피터노트북으로 돌려볼 수 있게 되어있으며, TensorFlow를 2.x대 버전으로 돌려도 가능하게 수정해뒀다.)
FullTokenizer
Target Data에 대한, BasicTokenizer와 WordpieceTokenizer를 진행한다. (하단 이미지 참조)
BasicTokenizer
말그대로 기본적인 텍스트 data 전처리 기능을 수행한다.
소문자 확인 (구글 BERT에서는 lower기능이 들어가있는데, 내꺼 기준으로는 빠져있다.)
unicode변환, null같은 필요없는 문자들 제거, 띄어쓰기 단위로 토크나이징 진행 (하단 이미지 참조)
WordpieceTokenizer
Target Data에 대한, BPE를 진행하며, 해당 BPE 값이 vocab에 있는지 확인하여, 없으면 [UNK]처리를 진행한다.
토큰의 길이가 너무 길어도(default 100), [UNK]처리되니 참고할 것.
Google은 Wordpiece(BPE) 기준이므로, 첫단어가 아니면 '##'이 붙어서 비교된다는 것에 주의할 것. (하단 이미지 참조)
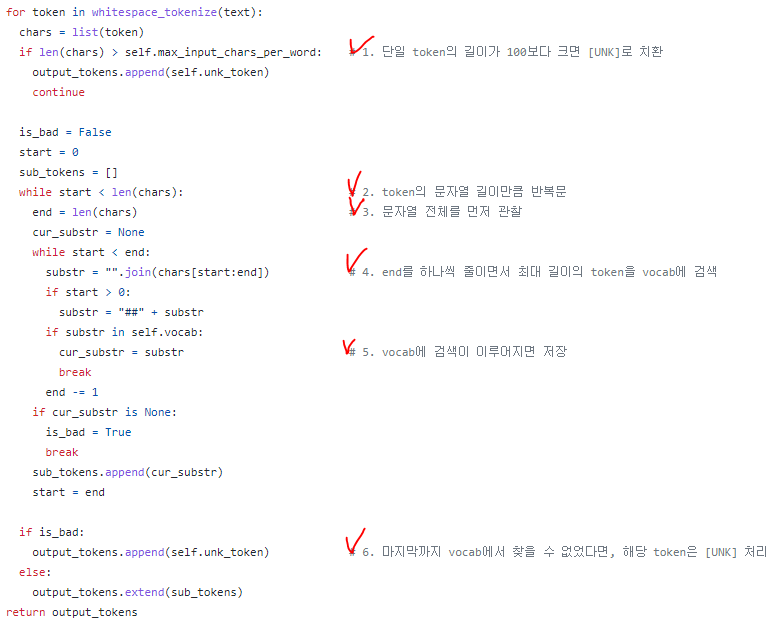
가장 첫 줄은 tokenizer의 선언부였으니까, 그냥 이런가보다~ 하고 넘어가면 되고, 가장 중요한 실제 수행부인 create_training_instances를 보자.
create_training_instances
위에서 정의된 Target Data와 vocab.list로 실제 Tokenize를 진행하게 되며, create_instances_from_document 메소드를 통해 Next Sentence Prediction(이하 NSP), masked_lm DataSet을 구성한다. (가장 중요한 부분이다.)
Tokenize
비유하자면, 우리 중학교 1학년 영단어장으로 고등학교 3학년 영어 독해를 풀이한다면, 당연 학습이 어려울 것이다. 때문에, 주어진 실제 Target Data(우리가 모은 실생활 영어문장)들과 얼마나 매칭을 시켜봐야하고, 또 얼마나 매칭이 되는지도 중요할 것이다. ([UNK]가 많으면 학습이 잘 될리가 없다.) (하단 이미지 참조)

현재 수행까지는 그나마 아직 사람이 알아볼 수 있는 2차원 list이며(shape = (문서,문장)), 얼마나 매칭이 잘 되는지도 output으로 알 수 있다. (하단 이미지 참조)
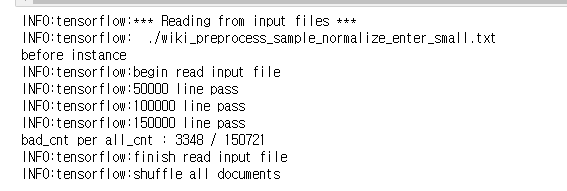
여기까지 진행되면, vocab.list와, vocab.list로 '전처리된 Target Data'가 완성되게 된다. 사실 Target Data는 (문서, 문장) 단위의 2차원 배열이므로, 일단은 documents라는 표현을 쓸 수 있겠다.
create_instances_from_document
바로 이어서 가장 중요한 documents로부터 실제로 학습 데이터를 구성하는 작업을 진행하게 된다.
크게 보면 2가지를 구성함.
(NSP 문장 결정, masked_lm)

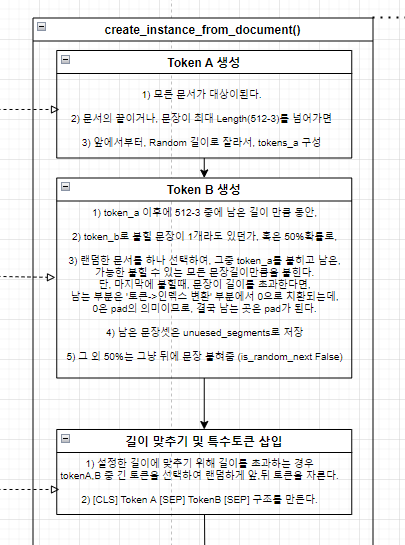
시작부분에 해당하며, 변수들을 선언한다. (하단 이미지 참조)
해당 변수들의 개념이 진행 간 중요하게 사용되어서 주석을 꽤나 많이 적어두었다.
이후의 과정들을 진행하면 차차 알게될 내용들이다.
1) 시작, token_a종료, token_b종료(=문장종료) 태그는 당연히 들어가야하므로 -3
2) BERT는 최대한 문장이 max_seq_length만큼은 있다는 가정하에 동작하는 것이나 다름없도록 동작한다.
최대한 max_seq_length를 가득 채울 수 있도록 노력하는데, 간혹 이러다보면 버려지는 짧은 문장들이 발생할 수 있다. 그런 경우에는, target_seq_length를 사용해서, 학습을 위해 사용될 tokens를 다이나믹하게 설정할 수 있다. (데이터의 불합리함(길이로인한)을 해소한달까?)
3) A,B 문장구조로 쪼개는 이유는 임의적으로 random하게 문장 구성을 재구성하여 '어렵게' 학습시키는 것으로,
next sentence pred가 잘 되도록 하기 위함이다.
=> 참고로 주석이 어떤내용은 구글 주석 번역이고, 어떤건 내가 써놓은거라서, 나도 이제와서 다시 돌이켜볼라니 뭐가 내가 썼던건지 헷깔린다...;;

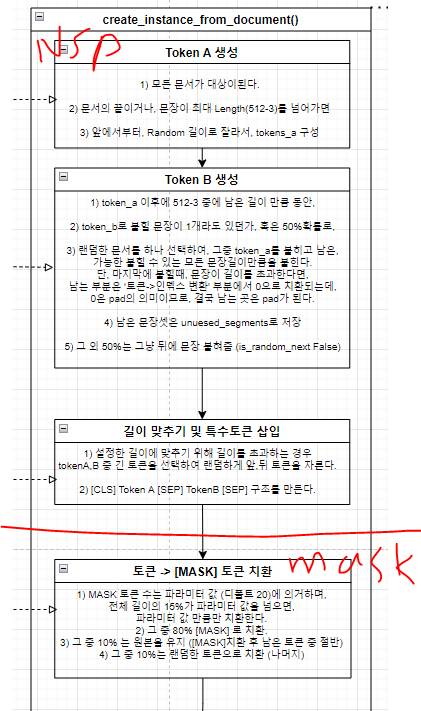
Next Sentence Prediction (NSP 문장결정)
실제로 token_a와 token_b를 결정하게 되는 구간으로, token_a와 그 다음의 sentence로 사용될 token_b를 골라내는데, 짧은 문장의 경우, 이 과정을 현재 문서에서도 random(token_a), 전체 문서에서 random(token_b)으로 뽑아대며, 이게 진짜로 다음문장인지, 다음문장이 아닐지도 확률로 선택하면서 다음문장(token_b)이 랜덤한 문장일거라면 최대한 랜덤하게 생성시키도록 노력한다.
다 적으면 소스가 너무 길어지니, 수행되는 프로세스 기준으로 정리해놓도록 하겠다.
1. max 길이의 구애받지 않고 일단 문장을 전부 붙힌다.
tokens_a
짤린 '''주석'''은, 해당 while문에서 진행되는 프로세스에 대한 사상을 간략하게 정리해놓은 것이다. (하단 이미지 참조)

1. 한 문서에서 문장들을 순회하면서, target_seq_length가 맞춰질때까지 문장들을 계속 붙힌다.
- tokens_a, tokens_b라고해서 2문장으로만 구성되는게 아니다. 짧으면 여러문장으로도 구성 가능함.
다만, 이때 구성되는 tokens_a는 무조건 다음 문장이 등장하겠다.
2. target_seq_length(사실상 랜덤길이)까지 붙혀진 문장들인 current_chunk를, 또 random 구간으로 짤라서 tokens_a로 설정한다.
tokens_b

1. tokens_a가 있어야 tokens_b가 의미가 있으므로, current_chunk 여부로 판단하며, random하게 50%확률로,
1) is_random_next=True
전체길이에서 tokens_a가 차지하고 남은 공간을 모든 문서에서 랜덤하게 1문서를 선택하여,
그 중에서도 랜덤한 위치에 있는 문장부터 순서대로 최대한 다 채울 수 있도록 (넘쳐도 좋다!) 문장을 계속 붙힌다.
tokens_a에서 a_end까지 다 사용한 나머지 뒷부분은 num_unused_segments로 저장되며, 남은 부분들은 다시
사용될 수 있으므로, i를 적용할때 감안하게 된다.
2) is_random_next=False

실제 다음 문장이 그냥 들어오면 되며, 때문에 a_end에서 chunk의 남은 곳을 전부 붙혀 완성된 이어진 문장을 만든다.
2. 위에서 신경안쓴 max길이를 조절한다.

max길이에 넘지 않으면 break이지만, 만약 넘는다면, tokens_a와 tokens_b중 더 긴 token에서 5:5로 앞뒤로 잘라준다. 참고로 문장 단위가 아닌 token 단위로 자름
3. 길이에 맞춰 구분자를 넣어준다.
[CLS] tokens_a [SEP] tokens_b [SEP]
형태로 만들어준다.
여기까지 진행되면, Next Sentence Prediction을 하기 위한 Dataset은 완성이 되며, 요약하면,
masked_lm
이후에는 masked_lm을 하기위한 처리가 진행된다.
내 Jupyter 소스에서는 모든 메소드를 풀어서 일렬화 시켜놔서, 호출부는 위와 같이 주석처리로 표현해뒀다.
[CLS]와 [SEP]를 제외하고, loss를 구하기 위한 label값을 구하기 위한 준비를 한 뒤 (masked_lm 변수 선언),
masked_lm_prob의 비율(default 15%)만큼만 mask를 생성하나, 만약 max_predictions_per_seq개수(default 20개)만큼을 넘어가면, 둘 중 최소값으로 선택하게 된다. (num_to_predict)

앞에서 정한 개수, 예를들어 20개라면, 20개중에 80%는 정말로 [MASK]로 치환, 10%는 원본, 10%는 랜덤하게 바뀐다.

나중에 설명을 할테지만 RoBERTa같은 경우, 위의 masking을 더 어렵게 한다던지 해서, 모델의 성능을 끌어올렸다.
사실상 메인 BERT를 이해하면, 파생되는 친구들은 이해하기 쉬우므로, 기본을 철저히 하는게 중요하다. (최근에 MS에서 DeBERTa를 내놨다고 해서 이것도 봐야할텐데...)
이후 과정은 필요한 변수에 담아서, TrainingInstance class로 선언하는 과정인데, TraningInstance를 소스를 적당히 바꾸면 data를 쉽게 로깅할 수 있게 활용할 수도 있으니, 꽤나 유용하니까 참고하길 바란다.
write_instance_to_example_files
지금까지 만들어놨던 NSP, masked_lm 데이터를 이용하여, 길이에 안맞는 값은 0을 채워준다거나, tokens to id 변환작업을 해준다거나, masked된 곳에 표시를 해둔다거나 하는 전처리된 Data를 이용하여, BERT 학습을 위한 Feature Dataset 구성 및 tf_record 형태의 data로 변환하는 과정을 거친다.
(필자는 test하느냐고 일단 주석처리 되어있다. 이후에 블로그 정리가 다 되면, 소스도 완벽하게 정리 해야겠다.)

여기까지 진행이 되면, 진정하게 BERT를 pre-training 할 수 있는 Feature와 label set이 완성이 된 셈이다!
(언어를 공부하기 위해, 단어장과, 문제집이 전부 완성되었다!)
번외,
Jupyter 기준으로 밑에 코드블락이 하나 더 있는데, 이 부분은 전처리된 데이터가 실제로 어떻게 떨어지는지 확인하기 위함이며, 완전히 Test소스이므로 무시해도 좋다. 또한, 각 data마다 파일이 생성되므로, 용량이 작은 낱개식 파일이 엄청 많이 나온다. (dupe_factor까지 True로 놓으면 진짜 무궁무진하게 나온다.)

또한, 이렇게 그냥 책읽듯이 쭉 읽어내리다보면, 나중에 tokens_a와 tokens_b가 막 중복되어 나오거나, 아니면 있는 값이 또 나오거나, 문장이 여러개거나 해서 당황하는 경우가 있는데, 일단 어느정도 위에서 설명은 되었지만.
dupe_factor에 따라 데이터가 masked만 달라진다던지해서 중복되는 것 처럼 생길 수 있으며,
문서가 매우 짧은 경우, tokens_a, b가 있더라도 매우 짧을 수도 있다.
tokens_a는 문서에서 시작위치만 random이 영향을 미치기 때문에, 문장이 여러개 있더라도 절대로 섞인 형태일 수 없으나, tokens_b는 완전한 랜덤 문서에서 랜덤 위치부터 뽑아오므로, 매우 운이 좋으면 tokens_a나 같은 tokens_b들 중에 중복되는 값이 생길 수도 있다. (당황하지 말것)
또한 이런 내용들로 인해 Data가 Overfitting될 소요는 없는지 잘 생각해보자...ㅎㅎ
마무리
일단 사실 한국어 Task에서 내가 겪어본 상태로는, 우리가 한국어 문장을 이해하기 위해선 통상 중요하게 생각하는 단어와 중요하지 않은 단어들이 존재한다. 이런 부분들을 잘 이용해서 create_pretraining_data를 진행한다던가, masked_lm이나 NSP의 비중 혹은 방식을 어떻게 설정해서 조정하느냐에 따라서도, 정확도나, 사용성 측면에서 개선될지도....?????ㅎㅎ
사실 내용을 보면 우리가 가장 먼저 접하는 BERT 논문과 사실상 들어가는 Masked 80 10 10 규칙이라던가 하는 부분들은 전부 정확하게 맞아 떨어진다.
소스 자체가 길다면 길고 간단하다면 간단한데(논문이랑 사실상 같은 내용이므로), 읽느냐고 고생이 많았고, 다음시간에는 실제로 pre-training에 들어가고자 하니, 많은 관심 부탁한다.
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| 딥러닝 TA 모델 - BERT (5-2 - run_pretraining (Transformer Encoder-Pooler)) (0) | 2022.01.08 |
|---|---|
| 딥러닝 TA 모델 - BERT (5-1 - run_pretraining (Embedding)) (0) | 2022.01.08 |
| 딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE) (0) | 2022.01.06 |
| 딥러닝 TA 모델 - BERT (2 - Attention) (0) | 2022.01.05 |
| 딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적) (0) | 2021.11.21 |




댓글