2021.11.21 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적)
딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적)
이전 시간으로, STT(ESPNet)를 어느정도 시작부터 끝까지 다 설명한 것 같다. 시작할때는 이 많은 걸 언제 풀어쓰나, 걱정도 됬었지만, 결국 어느정도 잘 정리가 된 것 같았다. BERT는 현재 진행 중이
shyu0522.tistory.com
에서 이어집니다.
Attention에 관련된 이야기는 LSTM으로 시계열 예측을 할 때, 내가 넣고 있는 Feature들에 대한 중요도를 알고싶어서, 시도 해본적이 있었고, 그 때 간략하게나마 적어놨던 아티클들이 있다.
https://shyu0522.tistory.com/11?category=974717
LSTM Attention 이해하기 - 서론
BERT 서론 회사에서 TA관련한 프로젝트를 할 일이 생겼다. 내가 나중에 시간이 되면 올리겠지만, 이전 회사에서 TA 관련된 프로젝트를 2개 해본것이 있었는데, 1. 회사 상품 평판 분석 2. Encoder-Decoder
shyu0522.tistory.com
https://shyu0522.tistory.com/12?category=974717
LSTM Attention 이해하기 - 어텐션 기초
Attention 예제 소스가 있는 git github.com/YooSungHyun/attention-time-forecast.git YooSungHyun/attention-time-forecast attention으로 시계열 예측은 할 수 없을까. Contribute to YooSungHyun/attention-ti..
shyu0522.tistory.com
바다나우, 루옹 어텐션을 논문을 읽고, LSTM 관점에서 사용가능하게 처리한 소스는 아래와 같다.
뭐 간략하게 설명하자면, 소스는 위에 나오는 아티클의 그림과 '완전히 일치'한다. 더 정확하게는, https://wikidocs.net/22893
아티클의 순차적인 진행과정을 그대로 파이썬으로 옮겨놓은 셈이다
Encoder(LSTM) -> Encoder_output(Layer Output, Hidden, Cell) -> Decoder(LSTM->Attention) -> Decoder_output(pred, Attention_Weight) -> loss 계산, 그라디언트 수정
절차는 똑같고, Attention 종류에 따른 계산 방식만 다르게 해놨으므로, 자세한 설명은 생략하겠다.
사실 짜놓고 생각이 든게, 짜는 것 보다, 이걸 어떻게 해석해서 내 데이터에 사용할 것인가를 고민하는게 더 중요해보여서, 그런 부분들을 시도적인 차원에서 접근해보도록 하겠다.
GitHub - YooSungHyun/attention-time-forecast: attention으로 시계열 예측은 할 수 없을까
attention으로 시계열 예측은 할 수 없을까. Contribute to YooSungHyun/attention-time-forecast development by creating an account on GitHub.
github.com
사실 Attention을 더 과거에 설명하고, 내적에 대해서 최근에 설명하긴 했으나, 다시 한번 정리해보면,
Attention은 Decoder에서 특정 타임시점을 예측하려할때, 전체 Encoder Input에서의 특정 영역과 상관관계를 고려(가중)하여, 예측을 하겠다. 라는 뜻이다.
Attention이라는 주제를 사실 시계열 예측, BERT에서 전부 다루고 있었으므로, 여기서 한방에 좀 설명을 해보자면,
시계열 예측에서의 Attention
내가 시계열 예측에서 Attention을 적용할 때 기대했던 바는,
1) 전체 time sequence를 1년을 준다면(encoder), decoder에서 1개월치를 예측할때, encoder에서 가장 영향력 있었던 기간을 최대한 더 참고해서 예측할 수 있지 않을까?
2) 특정 기간의 sequence의 feature를 준다면(encoder), decoder에서 1개월치를 예측할때, 해당 sequence에서 가장 영향력 있었던 feature를 표현할 수 있으며, 해당 값으로 모델이 잘 수렴하지 않을까?
라는 가설과 기대로 접근했었다.
즉, 사용하기 위해서는,
1) 바라보게 할 encoder의 데이터
2) 예측하고자 할 decoder의 데이터 (교사강요도 고려되어야함.)
- 교사강요를 사용하지 않고 무조건 1시간 혹은 1일을 24번, 7번 식으로 반복 예측하는 방식도 써봤었다.
3) Attention을 진행할 내적대상(Query, Key) 의사결정 (사실상 1,2번을 진행하면서 어느정도 결정될 사안일듯하다)
이 필요하다. (query=key=value라면 self Attention이라고 부른다.)
사실 LSTM으로 Attention을 진행하나, Word Embedding으로 진행하나, 둘 다 사람이 이해하기 어려운 숫자 벡터를 가지고 Attention이 진행되므로, 확인해보려거든 사실상 Attention Weight를 확인해야 그나마 사람이 좀 인지 가능한 수준으로 나온다.
1. 때문에, 최초에 데이터 설계를 할 때, 내가 정한 Shape 위치에 값이 뭐가 들어가는지 판단해보고,

2. 실제로 Shape를 그리고, 어떤 값을 내적할지 따져보며, shape에 문제가 없는지 직접 그려본다. (여기서 value는 결국 key)
3. 실제로 Score까지 진행했을때 나올 기대값을 한번 연산해본다. (현재 기준은 Bahdanau이다.)
적어도 이 구성은 이해를 하고 구성할 수 있어야, 기 개발되어있는 Torch 등의 Attention도 사용이 가능할 것이며,
만약 Attention을 직접 구현 혹은 변경해야 한다고 하더라도, 제대로 이해하고 변경할 수 있을 것이다.
(참고로 내가 git에 짜놓은 어텐션은 논문을 그대로 구현해놓은지라, 막상 성능은 엉망일지도...?)
내가 짠 소스에 대해서 검증은, 다른 개발자에게 검수를 요청해서 검증했으며, git에 올라온 타인이 짠 Attention 소스들과 직접 대조해보고 돌려보고 검증했다.
(사실 git에 올라온 사람들 소스도, 본인들이 쓰기 위해 짠 것을 올려서 그런지, 막히거나 소스 구성이 달라(예를들면 query등의 shape) output으로 검증하려해도 쉽지 않았다.)
아래 이미지는 실제로 돌려보면서 나오는 결과에 따라 스스로 계속 정리해본 것이다.
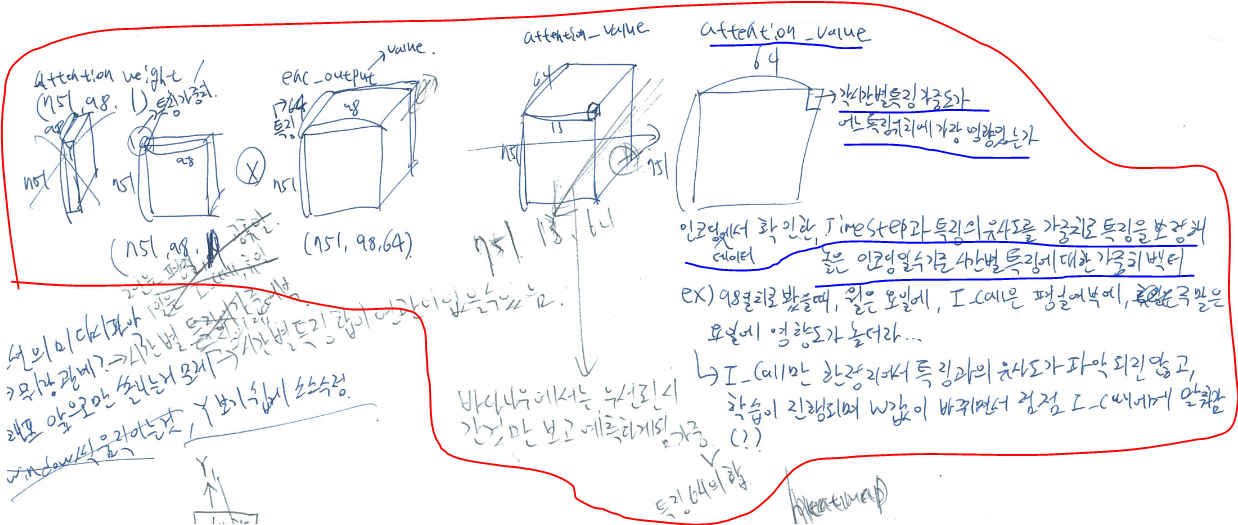

'특징 별로도 중요하면?' 이라고 써놓은 부분은, 내적을 할, 혹은 한, 결과가 결국 dense를 통해 시간순으로 flatten 되는 것이 아닌, 특징 중요도를 전부 살릴 수 있도록 처리해야된다는 의미였다.
일단 시계열 예측에서의 Attention을 정리해보자면,
핵심 1) 내적을 이용하여, 데이터의 상관관계를 어느정도 학습시켜가면서, 예측결과에 대한 정확도를 높힌다!
핵심 2) Attention을 구현하는 것 보다, 어떻게 본인의 데이터에 적용해서 원하는 결과를 얻어낼 수 있을지 고민하자!
3) 내가 가지고 있는 Feature와 그 것과 연관될 수 있는 data에 대한 이해와 가설 설정
4) input을 위한 data의 구성 (사실 교사강요 여부나, 값을 어떻게 쓸거냐에 따라서 numpy shape이나, 고려해야될 부분이 많다. 솔직히 논문을 보고 Attention 짜는 것 보다, 데이터 매번 전처리하는게 더 복잡하고 시간도 오래걸렸다.)
정도를 기억하면 되겠으며,
결국 분류문제가 아닌 회귀로 보이는 연속형 변수의 예측에 있어서도, Attention은 사용해볼 수 있다는 점을 강조하고 싶다.
BERT 에서의 Attention
BERT에서의 Attention은 word embedding이 어떻게 진행되며, loss를 계산하기 위한, masked lm, next_sentence_pred가 어떻게 역전파 관점에서의 영향을 미치게 되는지 이해해야, 완벽하게 이해했다고 할 수 있겠다.
때문에 여기서 설명을 다 하면 중간과정을 미리 설명하는 셈이 되므로, 오히려 더 어렵게 느껴질 수도 있으므로, 간략하게 학습의 관점보다는, Attention이 BERT에서 어떻게 동작하는지 위주로 보고, 이후에 실제 순서가 되었을 때, 구체적으로 한번 논의해보고자 한다.
일단 내가 논의하는 BERT는 Google의 BERT이며, RoBERTa, AlBERT를 전부 봤는데, 일단 Attention 관점은 같으며, RoBERTa만 리소스 효율화를 위해 shape만 살짝다르다.
여기서 token과 embed는 token과 그 token을 설명하기 위한 feature라고 생각하고 접근한다.
1. 실제 내적을 이용한 Att Score 구하기

query / shape : (token, embed) <- 여기서 embedding output은 feature와 같다.(stt에서의 fbank 값과 같은 원리)
key / shape : (token, embed)
dense(query) X dense(key) = Attention Score / shape : (token, token)
내적 계산에 의한,
(token, embed) X (token,embed) = (token, token)
형태의 vector가 생성되며, 내적의 원리에 의해, (token, token) vector는 query와 key의 token 관계값이라고 볼 수 있다. (Attention Score)
2. Softmax 해서 Att Weight 구하기

Attention 원리에 의해 각 token 간 관계’값’을 ‘비율’로 표현하기 위해 softmax 취한다. (Attention Weight)
3. Context Vector 구하기
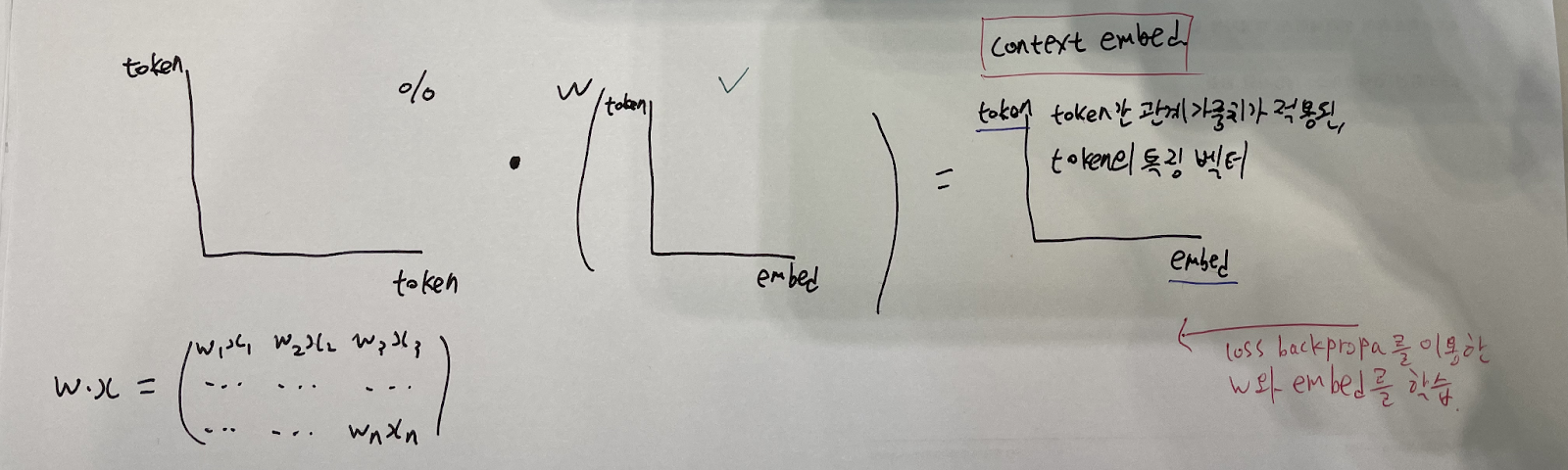
value / shape : (token, embed)
Attention Weight X dense(value) = context embedding vector / shape : (token, embed)
(token, token) vector만으로는,
1) 실제로 학습에 쓰일 수 없으며,(Feature인 embed shape가 없음)
2) 각 token간의 관계를 특징값에 투영(반영)시켜 관계까지 가중되어 학습되는 것이
비슷한 유형의 단어들을 묶어서 효과적으로 학습시킬 수 있을 것
이므로, value를 행렬곱하여, (token, embed) shape을 만들어줌과 동시에,
token 간의 관계 가중치를 특징값에 투영시켜 학습시킬 수 있게 된다. (context embedding vector)
이후에 이제 실제로 W가 학습해 나가는 과정과 Embedding Table의 변화는 역우도Loss 를 이용한 역전파 과정에서 어떤 값들이 학습되고 변화될 것으로 예상해 볼 수 있겠는데, 이 부분을 실제 BERT 설명 부에서 진행하도록 하겠다.
Attention 관점에서만 바라본다면,
사실상 내적과 softmax를 이용한 일반적인 Dot-Product Attention을 카테고리컬 데이터인 문자셋에 적용한 사례라고 볼 수 있겠다.
이와 같이 Attention에 대한 이해와 활용 방법을 근본적으로 이해한다면, 사실 어떤 Data Set에도 가설을 세워 시도적으로 Attention을 적용하고 실험해볼 수 있겠다.
Attention과 내적에 관련하여, 다른 Task지만 아티클을 상당히 많이 작성하기도 하였고, 뭔가 Attention Weight에 로망이 있는 것 같아서, 내가 개인적으로 좋아하는 알고리즘이기도 하다. (뭔가 해석 불가능한 딥러닝을 조금이나마 해석 가능하게 만들어 줬는 것 같아서.)
lime이나 shap을 쓸 수도 있겠지만, 조금 제한적인 느낌이기도 하고, 뭔가 Extension 쓰는 느낌이라...ㅎㅎ
Attention의 계산 방법론과 기본적인 Query, Key, Value에 대한 이해야, 많은 아티클들에서 다루고 있음에, 나까지 설명하면 더 내용이 길어질듯 하여, 소스만 무심하게 툭 던져놓고, 생략하였지만, 꼭 Attention Process를 소스로 구현해보거나, 내 소스와 비교하여 이해해보길 바란다. (이해하는데 상당히 도움이 되었다. 또한, 이해하기 쉬울 수 있도록 소스도 작성되어있다.)
뭔가 자연어 관련된 데이터에서만 Attention을 생각하는 경향이 강한 것 같은데, 사실상 ESPNet과 같은 Transformer 기반의 모델이라면 전부 채용하는 방식이며, 이렇게 개인이 구축할 수 있는 회귀형 Data에도 정확도야 어찌됐든, 가설을 세워서 적용해볼 수 있다는 것에 의의를 두었으면 하며, 여러가지 재밌는 시도들로 흥미로운 결과물들 얻길 바란다.
Attention은 어느정도 정리가 되었길 바라며, 또 안되었더라도, BERT를 진행하면서 한번 다시 마주할 것이므로, 다음시간에는 BERT Pre-Trained를 시작해보도록 하겠다.
번외로.
나는 사실 Attention을 이용한 연속성 데이터 예측에 조금 부정적인 편이었다.
2021.05.25 - [논문으로 현업 씹어먹기] - Time Forecasting에 있어 느낀, Attention의 한계
Time Forecasting에 있어 느낀, Attention의 한계
2021.04.19 - [논문으로 현업 씹어먹기] - LSTM Attention 이해하기 - 서론 LSTM Attention 이해하기 - 서론 BERT 서론 회사에서 TA관련한 프로젝트를 할 일이 생겼다. 내가 나중에 시간이 되면 올리겠지만, 이전
shyu0522.tistory.com
나름 공감도 많이 얻은 게시물이기도 한데, 뭔가 Transformer를 ESPNet처럼 Beam-Search같은 알고리즘과 비율을 둬서 쓴다거나. (아마 시계열이면 HMM같은 것도 되겠고.) 섞어서 비율조정을 해서 활용한다면 어떨까? 와 같은 궁금증이 조금 다시 생겨나버렸다.
아니면 내가 잘못 구현한 것일지... 이런 논문도 있기 때문에...!
https://arxiv.org/abs/1902.10877
Financial series prediction using Attention LSTM
Financial time series prediction, especially with machine learning techniques, is an extensive field of study. In recent times, deep learning methods (especially time series analysis) have performed outstandingly for various industrial problems, with bette
arxiv.org
최근에 HMM을 좀 파서 확실하게 이해를 했는데, 한번 해볼까 싶기도 하고...
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| 딥러닝 TA 모델 - BERT (4 - create_pretraining_data) (0) | 2022.01.07 |
|---|---|
| 딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE) (0) | 2022.01.06 |
| 딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적) (0) | 2021.11.21 |
| 딥러닝 STT 모델 - ESPNet (6 - Inference, Predict 시작!) (3) | 2021.11.15 |
| 딥러닝 STT 모델 - ESPNet (5 - 음성처리 도메인) (0) | 2021.10.25 |



댓글