2022.01.08 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (5-1 - run_pretraining (Embedding))
딥러닝 TA 모델 - BERT (5-1 - run_pretraining (Embedding))
2022.01.07 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (4 - create_pretraining_data) 딥러닝 TA 모델 - BERT (4 - create_pretraining_data) 2022.01.06 - [딥러닝으로 하루하루 씹어먹기] - 딥..
shyu0522.tistory.com
에서 이어집니다.
지난 시간에, Transformer에 입력으로 사용할 embedding 까지 만들어보았다. 이제 실제로 Layer를 지나가면서, output을 뽑아봐야 할텐데, Attention은 앞에서부터 계속 설명해왔던지라, BERT라고 크게 다를 건 없어서, 설명이 짧아지면, pooler까지 보겠고, 아니면 pooler는 따로 다뤄보도록 하겠다. (하지만 pooler만 다루기엔 또 아티클이 너무 짧아질 것 같아서...)
Transformer는 아래 ESPNet에서도 다룬적이 있으니, Encoder 정도는 참고해도 되겠다.
https://shyu0522.tistory.com/23?category=979870
딥러닝 STT 모델 - ESPNet (4 - Training 시작!)
BERT 관련 프로젝트를 진행하면서 쓰려니, 왔다갔다 정신이 없다...ㅋㅋ 그래도 시간이 좀 되는거 같아 바로 이어서 가보도록 하자. 2021.10.21 - [논문으로 현업 씹어먹기] - 딥러닝 STT 모델 - ESPNet (3
shyu0522.tistory.com
소스 참고
GitHub - YooSungHyun/deep-learning: 업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자
업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자. Contribute to YooSungHyun/deep-learning development by creating an account on GitHub.
github.com
Transformer Encoder (self attention)
소스에 보면, attention_mask 변수가 있는데, 해당 변수는 BERT를 학습시키기 위한 Mask가 아닌, Transformer에 있는 attention_mask 역할을 수행하는 것으로, 정확히는 pad mask를 진행한다. (padding을 학습시키지 않기 위함.)
Attention 진행 자체는, 내가 올려놓은 git 소스를 보면 알겠지만, 크게 특별할 것은 없고, (token, embed) 2차원 배열을 이용해서, 행렬곱에 softmax를 해주는 형태로, 내적 어텐션과 동일한 형태를 취하며,

scope에도 적혀있긴 하지만 from과 to가 같으므로, self-attention을 진행한다고 보면 된다. (참고로 Transformer의 encoder attention은 self-attention이다.)
이를 통해서 입력된 문장의 자기 스스로를 내적하여, 현재 단어와 각 단어 전체의 유사도를 파악할 수 있게 된다.
나는 이 부분이 N-gram과 가장 비슷하지만 다른 부분이지 않을까 생각한다.
N-gram은 단어를 유추할 때, 내가 결정한 N만큼의 거리의 단어들을 참고하여 유추한다는 것인데,
attention을 이용하면, N을 설정하지 않아도, Dynamic한 문장의 전체를 항상 전부 고려할 수 있기 때문이다.
multi-head attention은 마치, 같은 data를 이용하여 판단하는데, 여러명이 판단한 다음, 그들이 예측한 결과를 취합해서 최종 예측값을 산출하는 방식으로, 대충 감이 있다면 앙상블이랑 비슷하다고 느껴질 수도 있다.
앙상블이라고 하면 뭐 보팅, 베깅이 있을텐데, multi-head attention은 뭐 집계하거나 하진 않고 concat해서 linear layer로 통과시켜버리니, 굳~~~~~~~~~~~~~~~이 따지자면 보팅, 부스팅이 비슷하려나..? (이해를 쉽게 하기 위한 비유정도로만 생각하시길...)
Attention 소스를 하나하나 보기 보다는(주석도 다 달려있고, 내 git에 내적 소스를 같이 보면 쉽게 이해할만한 내용임), 실제로 token과 embed가 들어가서 어떻게 작용하는지는,
2022.01.05 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (2 - Attention)
딥러닝 TA 모델 - BERT (2 - Attention)
2021.11.21 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적) 딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적) 이전 시간으로, STT(ESPNet)를 어느정도 시작부터..
shyu0522.tistory.com
여기 이미 설명되어 있고, 여기서 존재하는 Trainable Param들이 어떤 작용을 기대해볼 수 있는지에 대해서 생각해보자.
사실 정확히 Trainable Param들은, 이후에 설명할 목적함수(loss)에 따라 학습되게 되나, 일단 진행되는 과정 중에 한번 짚고 넘어가보도록 하자. (이해가 안된다면, 나중에 loss Func쪽 설명을 읽고 다시 돌아와봐도 좋다.)
Attention의 실제 학습과 Embedding 값의 변화
설명에 앞서, 실제로 Attention이 진행되면서 Embedding 값이나, W와 매칭되는 Feature와의 변화를 Epoch마다 확인해보진 않아서, 내가 알고있는 지식으로써의 정황상 정보일 뿐이긴 하니, 아래 내용은 참고용으로 확인하길 바란다. 내 생각과, 같이 업무하는 동료들끼리 합의한 내용이다. (정황상 맞는 내용 일 것 같으나, 100% 확신하는 정확한 정보는 아니라는 얘기)
labels을 어떻게 구성하여, loss를 계산하고, 역전파 시키느냐에 따라, 학습되는 embedding 값과 dense의 w값은 상이하겠으나, BERT 기준으로 조금 축약시켜 이해해보자면,
masked lm만 loss로 활용할 경우,
Embedding값의 경우에는, 해당 위치의 masked를 맞췄을때 해당 문장에서의 각 위치별 단어의 관계를 가지고 역전파에 활용될 것이기 때문에, 비슷한 위치의 masked에서 등장했었을때, 맞은 혹은 틀린 상태에서의 embedding 값이 학습되게 되어, 결과적으로 비슷한 위치의 masked에서 유사한 단어 set로 embedding 값은 학습이 될 것이다.
W값의 경우에는, 실제로 학습된 embedding의 token으로, 주어진 문장을 가장 잘 표현할 수 있도록 학습될 것이다. (유성현과 문주혁과 이하영은 비슷한 embedding 값으로 학습이 될 것이지만, 각각의 W값은 ‘???가 밥을 먹었다.’ 에서 유성현, 문주혁, 이하영이 뭉쳐있는 embedding 좌표계를 최대한 가깝게(loss가 낮게) 지나가는 그래프를 그릴 수 있도록 학습될 것이다. (Markov Chain에서 잠깐 다뤘던, 머신러닝, 딥러닝, 기계학습을 같은 단어로 처리하지 못한다는 부분이 완벽하게 상쇄된다.)
NSP로 학습될 것으로 예상되는 것은,
Pooler의 Dense는 상관관계가 전부 Attention으로 계산된, 토큰값 1개의 Embedd output을 넣었을때, 다음문장인지 잘 예측할 수 있도록 학습이 될 것이며,
Embedding값의 경우는, 서로 관련 있었던 문장의 단어셋과 서로 관련 없었던 문장의 단어셋이 높은 상관관계 값이 나오도록 학습될 것으로 판단된다.
이후에는 Residual Connection을 진행한 다음, Fully-Connected 계층으로 넘어가게 된다.
Residual Connection
Residual Connection의 사상을 쉽게 설명하자면, 학습시 처음 값이나 정보는 학습이 진행 될 수록 그 값과 정보가 희석되어 희미해 진다. 이를 보완하여 학습 전의 정보를 상기 시켜주기위해 residual connection을 사용한다고 보면 된다.
대학교 4학년 졸업 시험이, 대학교 1학년부터 배운 전학기의 문제들 중에 출제된다고 가정하면, 엄청 막막하겠지만, 만약 대학교 4학년 1학기 공부 시점까지는 배운 지식을 까먹지 않고 100% 보존된다고 가정하면, 졸업 시험이 전혀 무섭지 않을 것이다. 역전파가 진행되면서, layer를 통과했던 값과, 그 직전값을 상호 보완하며 학습할 수 있으므로, layer의 깊이가 깊어지거나 한 경우에도 학습이 잘 되도록 보장되는 효과를 가져갈 수 있는 것이다.
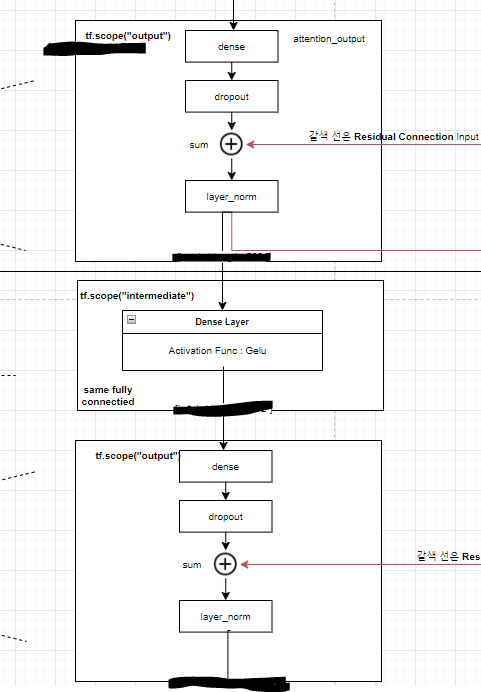
이렇게하면, transformer_model의 소스가 완성되게 되고, (all_encoder_layers)
sequence_output은 가장 마지막 계층인 output layer가 된다. (masked_lm loss 계산에 활용)
Pooler (NSP loss 계산에 활용)
Pooler 층에 대해서 설명된 아티클들이 많지 않아서, 조금 이해하기 어려운 부분들이 있었다.
(어쩌면 그냥 dense layer이기만 하니까, 단순하게 그런가보다 하고 넘어가는 사람들이 많은건가...ㅠㅠ)
왜냐면, 직접 debug를 진행하는데, 통상적인 시계열 예측을 진행한다면, window형태로 진행하거나, 뭐 예측한 값을 이용해서 그 다음값을 예측하거나 여러가지 방법이 있을 수 있는데, Pooler에서는 단어 token도 아니고, 고작 [CLS] 토큰 하나만을 넣고, Loss를 계산하는데 사용된다는 점이다. (단어 토큰이 하나도 들어가지 않는다!)
실제 소스 주석에도 설명을 상세하게 달아놓긴 했는데,
GitHub - YooSungHyun/deep-learning: 업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자
업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자. Contribute to YooSungHyun/deep-learning development by creating an account on GitHub.
github.com

일단 내가 설명으로 써놓을 내용들은, 발견된 사실이 아닌, 4인 합의된 그저 '이견없는' 정보임을 알린다.
참고하면 좋을 내용들,
https://inblog.in/A-gentle-introduction-to-BERT-Model-JfGFFXb97v
https://junklee.tistory.com/117
(가장 합리적으로 생각되는 답변)
Pooler에서 [CLS] Token 1개만 가지고 예측을 하여, loss계산에 사용해도 문제가 안되는 이유.
1. [CLS] 가 문장의 모든 token의 정보를 가지고 있다. (self attention을 통해)
2. Is Next, Not Next 로 이어지는 문장과 아닌 문장을 알고있다. (labels가 있으므로)
3. 이어지는 문장들의 [CLS]로 학습을 시켜 이어지는 문장을 예측한다. <- Pooler의 행위
+ 반드시 [CLS] 여야 하는가? [CLS] 토큰만 모든 문장의 정보를 가지고 있는게 아니다.
CLS 토큰만 모든 문장의 정보를 가지고 있는 것은 아니다.
self-attention이므로, 모든 토큰이 전부 정보를 가지고 있다.
다만 정보량의 객관성 측면에서 바라보았을때,
한 문장(1 batch) 안에서 CLS만이 유일하게, 단어간 상관관계의 영향도가 상대적으로 문장에서 가장 작은, 결국 버릴값. 그러므로, 가장 객관적으로 문장의 상관관계를 고유하게 가질 수 있는 값 이다.
예를들어 '밥'이라는 단어로 NSP를 진행하면, '밥'이 등장한 Training Data Set에서 문서의 위치, 문장의 위치마다 상관관계값이 계속 달라질 것이며, 자기 스스로와 상관관계는 무조건 가장 높을 것임.
(단어 토큰으로 loss 계산하면 비효율 적인 이유)
=> 정보량이 객관적이지 못하며, Train Data Set에 귀속적임
'[CLS]'는, 모든 train set에 무조건 존재하며, 모든 단어 데이터를 최소 1회는 마주함.
([CLS] 토큰이 효율적인 이유)
=> Train Data Set에 귀속적이지 않음.
또한 무조건 0번째 array 값이므로 다루기 쉽고, 자기 자신과의 attention 값이 높아도, 예측에선 사용되지 않은 값임.
=> 위치나, 등장에 따라 정보량이 가중되지 않는, 가장 객관적인 값
output이 sequence_output일 때가 있고, pooled_output으로 구분되는 이유
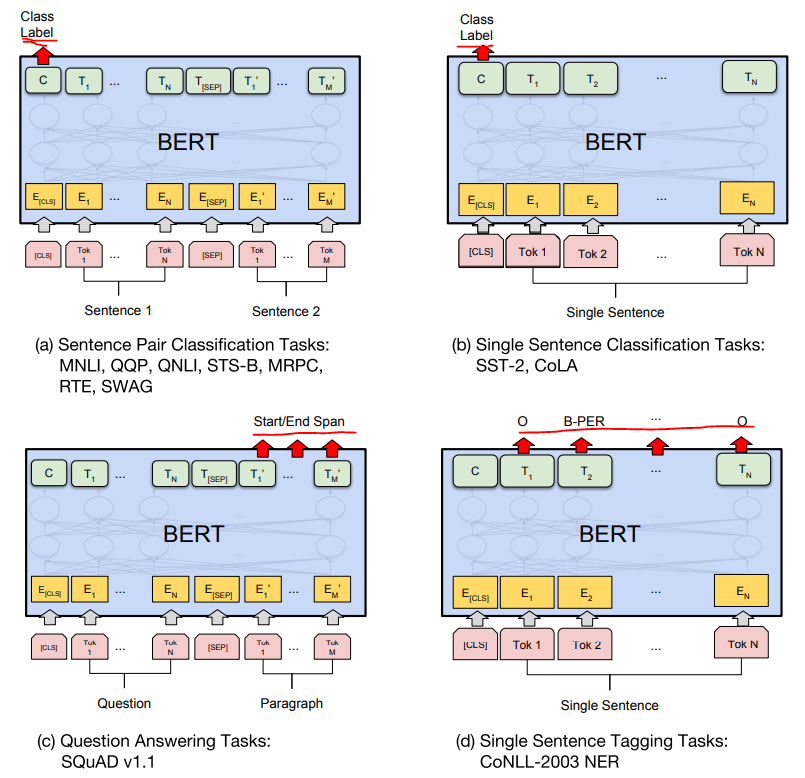
BERT논문에 보면 각 Fine-Tunning Task별로, Pre-Training 모델의 output을 다르게 사용한다.
위의 2가지 케이스((a),(b))는 Class Label([CLS])인 pooled_output을 사용하는 예제이고,
밑에 두가지 케이스((c),(d))는 sequence_output을 사용하는 예제이다.
목적에 따른 pre training 모델의 output을 판단하여 사용하는 것이 중요하겠다.
여기까지 진행되면, 이제 문제집을 주~~욱 풀어보면서 음 내가 여태까지 배웠던 기억으로는, 정답이 이것인것 같아...!
하고 답을 다 작성해놓은 상태까지 됐다고 볼 수 있다.
이제 Transformer보다 중요한 loss를 계산하는 방법만이 남아있다. (채점!과 복습!)
이후 시간에 이어서 알아보도록 하자.
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| 딥러닝 TA 모델 - BERT (5-4 - run_pretraining (Optimizer)) (0) | 2022.01.11 |
|---|---|
| 딥러닝 TA 모델 - BERT (5-3 - run_pretraining (NLLloss(masked_lm, NSP))) (0) | 2022.01.10 |
| 딥러닝 TA 모델 - BERT (5-1 - run_pretraining (Embedding)) (0) | 2022.01.08 |
| 딥러닝 TA 모델 - BERT (4 - create_pretraining_data) (0) | 2022.01.07 |
| 딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE) (0) | 2022.01.06 |




댓글