2022.01.07 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (4 - create_pretraining_data)
딥러닝 TA 모델 - BERT (4 - create_pretraining_data)
2022.01.06 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE) 딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE) 2022.01.05 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 T..
shyu0522.tistory.com
에서 이어집니다.
이제 대망의 pre-training 시간이 도래했다.
(사람으로 따지면, 단어장과 학습지가 있으니, 실제로 풀어보면서 공부할 시간!)
fine-tunning도 작성할 생각이긴 하지만, 현재 pre-training처럼 flow까지 구체적으로 공개하긴 어렵겠다.
다음시간에는 파생 BERT들(AlBERT, RoBERTa)을 다루고자 하는데, 그 이후에는 전반적인 흐름이나 나의 느낀점 등을 위주로 작성되지 싶다.
(아무래도 노하우이기도 하고 민감할 수 있는 부분이라...)
전체적인 Flow로 보면,
1. 학습 과정 세팅 (TPU, 분산학습 등)
2. tf.estimator를 이용한 학습을 위한 model parameter 세팅
3. do_train
1) 선언된 estimator를 이용한 학습 시작
- Embedding
- transformer encoder
- masked_lm_loss, NSP loss를 이용하여 gradient optimize (NLL loss를 이용한 역전파)
- pooler
=> 여기서 또 다뤄볼만한 이야기들이 있다.
4. do_eval (모델 검증)
의 절차로 진행되는데, 일단 기본 개요, Embedding, Transformer, NLL loss(masked_lm, NSP), pooler로 총 한 7~8개 정도의 이야기하고자 하는 내용들이 있으니, 절대로 이번 아티클에서 마무리되진 않을 것 같다.
(이전시간에 create_pretraining_data 부분만 봐도 너무 길어서, 내가 썼지만 내가 읽었을때 좀 지치는 감이 있었음... 양 조절해서 분할해서 작성하겠다.)
가장 초반에 TPUEstimator를 선언하는 부분은 생략하겠다, json 파일에서 BERT학습을 위한 파라미터 값을 들고와서, TPU->GPU->CPU 순으로 사용할 수 있는 장비를 판단한 다음, TPU의 경우, 병렬처리 제약점들을 고려해서 Data를 구성하고, 이후에는 실제로 학습에 사용될 model 소스를 준비해서 만들어준 다음에, estimator train 돌리는 과정이다.
(주석만 참조해도 따라가는데 크게 어려움은 없을텐데, '함수 인자'같은 파이썬 기초지식이 없으면, 소스를 '따라가는 것'이 어려울 수 있다. file find를 이용해서 필요한 부분들을 부분부분 보고 이해하거나 하는 것도 방법일듯)
결과적으로 train이 시작되게 되면, do_train에서의 절차가 feature 값들을 이용해서 하나하나 진행되게 된다.
(tpuestimator의 model_fn 구현체로 학습이 시작되게 됨.)
model_fn을 보면,

크게 3영역으로 나누어볼 수 있는데,
1) feature 선언
2) BertModel 선언 (BertModel의 __init__에서 실제 학습에 필요한 embedding, transformer encoder가 진행)
3) 모델 loss를 계산
의 절차로, BertModel을 엄청 큰 하나의 딥러닝 레이어라고 생각하면, 데이터 인풋 -> 모델레이어 진행 -> loss output
이라는, 평이한 학습의 형태를 지닌다.
가장 중요한 부분은 BertModel의 __init__과, 실제로 loss가 계산되는 get_masked_lm_output, get_next_sentence_output 인데, 아마 이번시간에는 __init__의 embedding 설명하다가 끝나지 않을까 싶다.
BertModel의 구현체는 modeling.py이니 해당 파일로 넘어가보도록 하자.
(참고로 ipynb 말고도 py 파일에도 전부 상세하게 주석을 달아놓았다.)
(다만 업무간 작성한 주석은 아니고, R&D간 작성된 개인 소스의 주석이므로, 아직 정리된 상태는 아니며, 이전에 잘못써놓았던 내용 이후에 제대로 알게된 사실을 써놓은 경우도 있어서, 잘 걸러서 이해를 잘 해야할 것이다.)
(그래도, 소스를 차근차근 보면서 이해하는 사람은 컨셉을 명확하게 이해할 수 있도록 작성했다고 생각되니, 학습을 목표로 차근차근 하나씩 따라가보는 것을 추천한다.)

modeling.py 내용들 부터는 variable_scope가 명확하게 잘 표시되어있어, 소스를 이해하는데 큰 어려움은 없겠다.
논문에서 다루는 내용과 동일하게, word_embedding과 token_embedding, position_embedding을 지원한다.
word_embedding은, 문장벡터를 vocab 단위로 임베딩하며, 학습될 임베딩 테이블은 '절단된 표준편차 정규분포'로 랜덤화해서 최초 선언해놓는다.
(embedding_table은, 해당 word token을 설명할 어떤 feature라고 볼 수 있다. (마치 원핫 표현 같은) 다만, table을 학습 가능한 trainable param으로 두고, 특정 목적함수(transformer에서의 행위 및 loss계산과 같은)에 맞춰, 가장 word token을 잘 설명할 수 있도록 학습될 것이다.)
HMM 아티클을 봤다면, 거기서 실제로 학습을 위한 최초 변수 선언 과정에서, 랜덤이 아닌 데이터의 비율로 최초 선언했던 것이 기억나는가? 초기화를 꼭 절단된 표준편차 정규분포로만 해야하는가?
2022.01.03 - [Python과 확률] - 조건부 확률부터 마르코프까지 - 5-4) HMM Learning Task (Training)
token_type_embedding은, tokens_a, tokens_b를 구분하기 위한 2진 분류 문제를 위한 embedding으로, 차원이 작을 수록 one_hot이 빠르다고 하여, embedding_lookup을 사용하지 않고 one_hot으로 처리하여 trainable param으로 사용한다. (즉 이 녀석도 학습되어, 각 feature들이 tokens_a, tokens_b를 잘 설명하도록 되길 목적함수를 통해 기대해본다.)
position_embedding은, 각 token(단어)들의 순서를 학습시키기 위한 embedding으로, 단어 순서가 결국 array index랑 1:1 매칭이니까 굳이 embedding_lookup같은 걸 복잡하게 쓰지 않아도 된다. (trainable param이다.)
즉 embedding 진행의 최종 output(embedding_output, embedding_table)은 전부 trainable parameter이며, layer의 구성과 그로 인한 loss 함수에 의해, 어떤 특정 목적을 지니고 학습을 진행해 나가게 된다. (그 목적에 대해서는 loss와 attention을 설명할때 자세히 다루겠다.)
==> trainable parameter라고 생각한 이유 : get_variable의 trainable 파라미터는 1.x대 Tensor기준 True이다.
Embedding의 전체 Flow
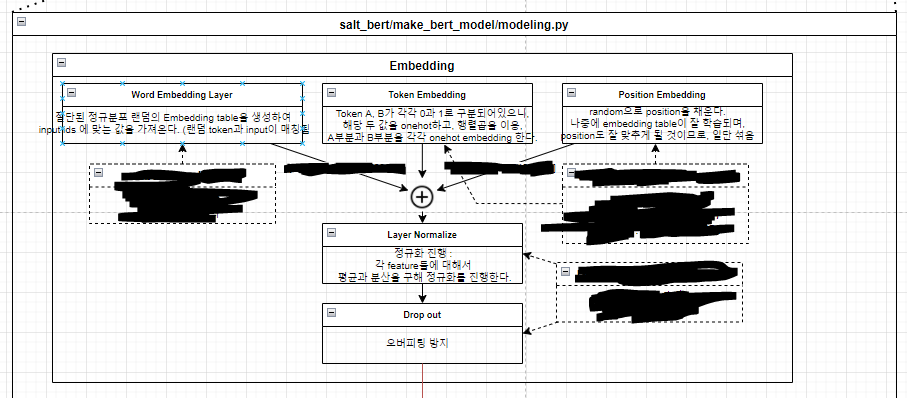
특징을 잘 학습할 수 있도록 구성을 했으니, 이제 실제로 문제를 풀어보면서(layer throughput, predict), 채점을 통해 언어를 최대한 잘 학습하는 과정(loss, optimize)만이 남아있다.
우리가 평소에 이야기하는 언어의 단어, 문장을 학습할때, 예를들면 if ~~~, then ~~~ 구문을 배운다던가(token_type_embedding), 주어 다음은 동사를 배운다던가(position_embedding), 주어에는 I,he,sunghyun 등이 가능하다라는걸 배운다던가(word_embedding), 이런 언어 구성에 대한 특징들을 실제로 문제집(목적함수)으로 배우게 되길 희망하는 것과 비유해볼 수 있겠다.
이런 목적과 달성을, cost와 수렴/발산으로 이해할 수 있겠고, 이런 비유적 설명들이 오해없이 습득하는데 긍정적인 영향을 미쳤으면 좋겠다.
전반적인 시작과정과 Embedding까지 설명이 되었으니, 이번시간은 여기까지 하도록 하고, 다음 시간에는, 실제 Transformer Encoder 과정을 보도록 하겠다.
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| 딥러닝 TA 모델 - BERT (5-3 - run_pretraining (NLLloss(masked_lm, NSP))) (0) | 2022.01.10 |
|---|---|
| 딥러닝 TA 모델 - BERT (5-2 - run_pretraining (Transformer Encoder-Pooler)) (0) | 2022.01.08 |
| 딥러닝 TA 모델 - BERT (4 - create_pretraining_data) (0) | 2022.01.07 |
| 딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE) (0) | 2022.01.06 |
| 딥러닝 TA 모델 - BERT (2 - Attention) (0) | 2022.01.05 |




댓글