2022.01.16 - [딥러닝으로 하루하루 씹어먹기] - BERT로 시계열 데이터 분류 Task는 할 수 있을까? (1 - 근무 시간표 예측?)
BERT로 시계열 데이터 분류 Task는 할 수 있을까? (1 - 근무 시간표 예측?)
2021.05.25 - [논문으로 현업 씹어먹기] - Time Forecasting에 있어 느낀, Attention의 한계 Time Forecasting에 있어 느낀, Attention의 한계 2021.04.19 - [논문으로 현업 씹어먹기] - LSTM Attention 이해하기..
shyu0522.tistory.com
에서 이어집니다.
회사에선 회사일하느냐고, 진행이 매우 느린점은 양해바란다. (그래도 내가 개인적으로 너무 궁금하고 해보고 싶어서, 최대한 열심히 해보는중)
일단 생각해보니까, CLS랑 SEP는 의미가 없을 것 같다. 일단 문장 순서를 바꾸지도 않을 것이며, pooled_ouput을 안쓸테니, CLS 토큰은 의미가 없다. 그래서 Data는 7 Sequence를 가지는 근무카테고리 값이 되었다.
완성된 Fine-Tuning Layer

dropout까지는 똑같고, 이후에 LSTM Layer를 쌓고, many to many로 학습되야 하므로, TimeDistributed를 사용해줬다.
nn.CrossEntropyLoss는 일단, NLL Loss를 사용한다. (softmax까지 다 쳐준다.)
Dimension에 대한 고민이 조금 있었는데, 7X4 형태로 2차원 배열이 떨어지면, 거기서 행단위로 softmax가 잘 되나 궁금했는데, (각 날짜별 max값이 궁금한 것이지, 전체 Sum이 1이 되면 안되니까...)
nn.CrossEntropyLoss는 즉, 여러 Sequence가 나오면, 행단위로 loss계산되서, mean Reduction해서 사용된다.
결론.
간단하게 7일치 Data를 넣어서, 7일치 Data를 예측하는, 약간은 점예측 같은 형태로 접근해봤는데 (window 사용X)
모든 Data가 오프에 편향되었다. 그리고, 정확도는 43%정도에서 오를 생각을 안했다.
일단 그도 그럴게,
Data 구성자체가, 오프에 편향되어있다보니, Overfitting되는 경향도 있겠고, 확실히 그 때문인지, Attention으로 학습될 word embedding 테이블의 Feature들의 상관관계를 조사해보면,
Embedding Feature들도 오프에 비교적 편향되어있는 것으로 판단된다. 즉, Attention을 치더라도, 오프 Feature에 Attention Weight값이 편향될 가능성이 높으며(현재 내 모델은 position, token embed는 없다!), 이렇게 LSTM 학습시켜봐야, 오프로 예측할 확률만 높아질 것이고,
time_distribute를 한 것 역시, 결국엔 각 Dense에 LSTM output을 대응해서 예측하는 것이므로, 오프로 편향되면 모든 예측값이 오프로 나올 것이다.
일단 해결해보기 위해 생각해본 방법 네가지 정도는,
1) Time Series를 더 길게 넣어서 7일을 예측해보는 것
=> 해당 방법은 좀 비관적이다, 누적될 수록 오프 값 편향이 더 가중될 수 있으므로
2) Attention에서 오프에 대한 웨이트 가중치에 패널티를 주는 방법
=> 비관적이진 않으나, 적용이 어렵지 않을까? (정확하게 내적의 output 값중 어떤 부분이 오프에 영향을 크게 미칠지 알 수 없다. 때문에 기울기 역전파 등의 과정에서 오프로 예측해서 맞췄을때 변화값을 줄인다던가 해볼 수는 있을 것 같은데....)
3) 포지션 임베딩과 토큰 임베딩을 전부 활용한다.
=> 결국 월~일까지의 7일 시퀀스를 사용하므로, 토큰 임베딩은 모르더라도, Position Embedding은 사실 중요한 값이었겠다. 라는 생각이 갑자기 스쳤다...(이걸 이제 생각하다니)
4) pre training이 뭔가 단단히 잘못되었다.
=> pre-training과정에서 정확도가 100%가 나오는 점은 분명 이상함.
사실 패착요인으로 생각되는게, Self Attention이 과연 정말 필요했을까? 를 고민해봤어야 했는데...라는 생각이 들었다.
지금 나의 문제는 7일치 데이터 내에서 유사도나 상관관계를 이해하는 것 보다는, 현재 7일치로 다음 7일치를 예측하는 것이 더 중요한 Task였다.
즉, self attention이 중요하지 않다는 것은 아니나, 정확하게는, 현재 7일치의 상관관계를 참고해서, 다음 7일치와의 관계를 학습시키는 것이, 더 정확하지 않았나. 라는 생각이 든다.
처음에는 어느정도 LSTM으로도 위와 비슷한 현상이 나타나지 않을까, 라고 생각은 했지만, 차라리 Transformer Decoder를 이용해서, 교사강요로 학습시키는게 낫지 않았을까 라는 생각이 든다. (BERTSum처럼...?)
일단 위에서 분명히 짚고 넘어가야되는 점들(pre training loss확인 등)은 분명히 한번 확인을 해야 할 것이고,
다음 시간에는 Transformer Decoder를 활용해본다던가,
아니면 차라리 BERT Encoder를 사용하지 않고, 순수하게 Transformer Encoder를 활용해서 그냥 Transformer 모델로 해결해볼까 싶기도 하다.
일단 쓸 일이 있는 사람이 있을지는 모르겠으나, 구조, 설계상 내가 짜놓은 BertForTimeSeriesClassfication은 이상이 없는 것 같기는 하다. (실제로 BERT Encoder이후로 쓰는게 유의미한 사람이 있다면...?)
개인적인 부분이라서, 데이터 부분만 빼놓은 소스를 git에 올려놓았다.
유용하게 활용들하시길!
https://github.com/YooSungHyun/deep-learning/tree/master/BERT_GYM/time_schedule_bert
GitHub - YooSungHyun/deep-learning: 업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자
업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자. Contribute to YooSungHyun/deep-learning development by creating an account on GitHub.
github.com
ETC.
아, 그리고 tf 모델 HuggingFace로 전환하기 위해서,
GitHub - nlpyang/pytorch-transformers: 👾 A library of state-of-the-art pretrained models for Natural Language Processing (NLP
👾 A library of state-of-the-art pretrained models for Natural Language Processing (NLP) - GitHub - nlpyang/pytorch-transformers: 👾 A library of state-of-the-art pretrained models for Natural Langua...
github.com
이 녀석을 좀 수정해서 사용했는데, 모델의 layer 자체를 수정했다면, 꼭 변환 후 Layer 상황을 체크 해봐야한다.
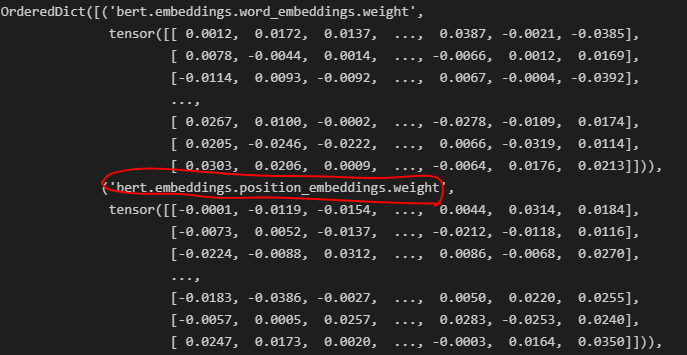
분명히 내가 만든 BERT에서 날리고 썼는데 왜 살아있나 찾아보니, HuggingFace BERT를 쓰는쪽에서 제거를 안해줘가지고, 계속 init value로 재생성되고 있던 것이다. (절단된 표준편차 Random을 쓰니까, 해당 값은 tf -> torch 할때마다 바뀐다. word_embeddings.weight는 안바뀜...)
무지성으로 썼다가, 재현되지 않는 이상한 모델이 만들어질 수도 있으니, 이런부분들은 소스를 한번 보고 쓰느냐, 마느냐에서도 실력차이가 갈리는 것이 아닐까...
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| HuggingFace Datasets Audio에서 이제 pcm을 지원합니다. (0) | 2022.08.15 |
|---|---|
| HuggingFace에서 kenlm 사용하기 (0) | 2022.08.15 |
| BERT로 시계열 데이터 분류 Task는 할 수 있을까? (1 - 근무 시간표 예측?) (0) | 2022.01.16 |
| 딥러닝 TA 모델 - BERT (6 - BERT의 파생 (ALBERT, RoBERTa)) (0) | 2022.01.14 |
| 딥러닝 TA 모델 - BERT (5-4 - run_pretraining (Optimizer)) (0) | 2022.01.11 |




댓글