2022.01.11 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (5-4 - run_pretraining (Optimizer))
딥러닝 TA 모델 - BERT (5-4 - run_pretraining (Optimizer))
2022.01.10 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (5-3 - run_pretraining (NLLloss(masked_lm, NSP))) 딥러닝 TA 모델 - BERT (5-3 - run_pretraining (NLLloss(masked_lm, NSP))) 2022.01...
shyu0522.tistory.com
에서 이어집니다.
여기까지 진행했으면, 기본적인 BERT의 pre training과정에 대해서 알아보았다.
BERT의 pre training 과정을 잘 이해했다면, 이제 BERT의 파생인 녀석들도 이해할 준비가 되었으며, 실제로 소스를 보더라도 어느정도 거부감없이 접근할 수 있다.
이번 시간에는 BERT의 파생인 ALBERT, RoBERTa에 대해서 알아보고,
차이점은 무엇인지 고민해보는 시간을 가져보도록 하겠다.
1. ALBERT
google-research GIT 기반의 소스로, TensorFlow 기반이며, BERT와 같은 카테고리로 묶여있는만큼, 소스도 BERT와 비슷하며, 이해하기 쉽다. (그래서 먼저 알아보도록 하겠다.)
https://github.com/google-research/albert
GitHub - google-research/albert: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations - GitHub - google-research/albert: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
github.com
차이점
1) SOP (sentence order prediction)
loss를 계산하는 것은 NSP와 같으나, 중요한 것은 create_pretraining_data.py쪽이 되시겠다.
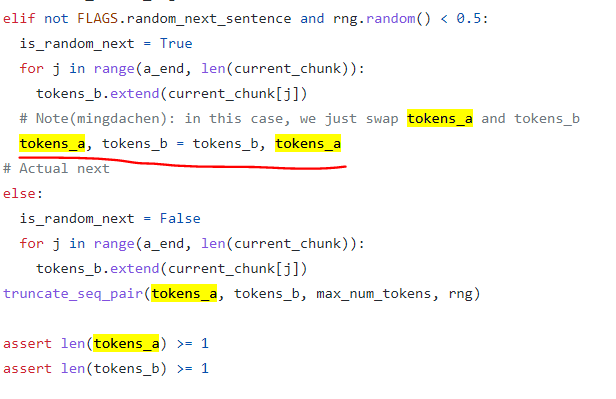
tokens_a와 b를 바꾸어, 문장의 순서가 옳바른지를 판단하는 것으로, NSP보다 Fine-Tuning Task에서 성능이 좋았다고 한다. (이 부분은 나도 조금 더 봐야할 부분이긴한데, 통상 pre training 모델의 검증 결과가, 꼭 fine-tuning까지 연결되지는 않았다는 점이다. 예를 들면, pre training에서 evaluation했을때 loss가 증가하여도, 실제로 fine-tuning에서 개선되는 경우가 있었음.)
사실상 loss는 말만 get_sentence_order_output으로 바뀌어 있을 뿐, 안에서 동작하는 바는 BERT의 NSP와 동일한 2진 분류 loss task이다.
2) Factorized Embedding Parameterization
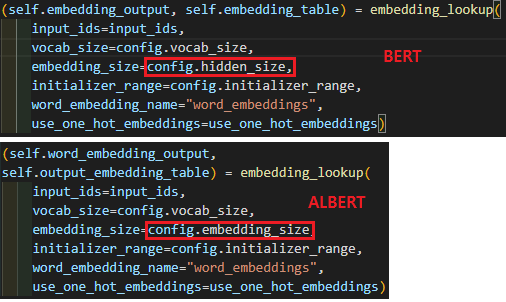
embedding_size를 일단 BERT보다 작게 잡아서 Embedding을 진행한 후, 이후에 Attention을 진행하기 위해서 hidden_size와 차원을 맞추기 위해, Dense Layer를 추가해서 맞출 수 있도록 하였다.

논문에서 설명되기로는, hidden_size의 역할은 Attention에서 벡터간의 상관관계까지 투영되어있는 벡터이지만, embedding에서의 벡터는 단순히 token을 설명하기 위한 벡터일 뿐이며, BERT의 목적은 벡터간의 문맥적 상관관계를 학습하기 위함이기에, embedding 벡터가 굳이 클 이유가 없다는 것으로, 실험적 결과를 통해 설명되어져 있다.

어찌보면 embedding은 ALBERT의 관점으로 무조건 파라미터를 축소하여 사용하는 것이 더 나을지도 모르겠다는 생각이 든다.

시간복잡도의 경우 행렬곱이라는게 사실상 2중포문을 활용하는 지라, O(N X M)만큼이 걸리기 마련인데,
embedding에서도 역시나 O(단어수 X 히든사이즈수)만큼 드는걸, embedding 사이즈를 줄여서 적용하면,
O(단어수 X 임베딩수 + 임베딩수 X 히든사이즈수)가 되는데, 나는 이게 더 커지는거 아닌가? 했는데 아니었다.
예시) 보캡수 30000, 히든사이즈 768 = 약 2300만
보캡수 30000, 히든사이즈 768, 임베딩수 128 = 약 394만
=> 속도적 성능도 훨씬 좋아진다....
3) Cross-layer parameter sharing
소스에서는 'num_hidden_groups' 변수로써 설정되어지는 값으로,

예를 들어서 num_hidden_layers가 12, num_hidden_groups가 6이면, layer_idx는 0부터 11까지 돌아가니,
0,0,1,1,2,2....와 같은 식으로 group이 묶여지게 되며(6개), variable_scope를 이용하여, trainable parameter를 공유하게 된다.
일단 소스에서는 해당부분이 Attention의 전체를 감싸고 있는 것이나 다름이 없어서, 논문상으로 확인해보면,

소스는 all-shared 기준으로 작성되어있다. 정확도야 크게 차이는 나지 않지만, LITE BERT라는 관점에서 Parameters가 가장 적은걸 선택하는게 논문 컨셉이랑도 맞으니, all-shared 기준으로 소스가 작성되어있지 싶다.
또한 참고할만한 내용은, ALBERT는 일반적인 내적 어텐션이 아닌 Scaled 내적 어텐션이니 참고하길 바란다.
이 외의 과정은 일반 BERT와 동일하므로, 딱히 특별할 것은 없다.
2. RoBERTa
Huggingface의 소스를 참고하였다.
Huggingface의 소스는 각 Downstream Task(Fine-Tuning Task) 별로 소스도 제공된다는 점이다.
(다만 조금 특별한 부분도 있으니 밑에서 알아보도록 하겠다.)
참고로 RoBERTa는 ALBERT와 다르게 Embedding은 일반 BERT와 같이 hidden_size로 정의된다.

GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, a...
github.com

차이점
1) Full Sentences + NSP 제거
NSP는 실제로 소스에서 없다. 다만, TFCausalLanguageModelingLoss, TFMaskedLanguageModelingLoss으로 제공되어서, lm loss를 선택적으로 활용할 수 있다.
구글 BERT는 일단, 문서내에서 만큼은 최대한 token의 수를 채우려고 하나, 문서가 매우 짧은 경우, 불가피하게 pad를 사용하게 된다. (Segment Pair+NSP)
이를 타개하고자, RoBERTa에서 접근한 Full Sentences 방식은, 문서를 넘어가더라도, 최대한 token을 채우자는 것이다.

huggingface에서는 일단 roberta의 dataset처럼 구성할 수 있는, extra separator token을 적용한다던지 하는 소스는 있는데, create_pretraining_data.py와 같은 한큐에 만들 수 있는 소스는 못찾았다 ㅠㅠ

RoBERTa의 경우 논문은 PyTorch의 fairseq git에 귀속되어있는데(facebook), 정확히는 facebook에서 사용하는 모델 아키텍쳐의 transformer를 사용한다면 전부 넣어놓고 쓰고있어서, RoBERTa에 Fit한 소스만 골라보기 조금 어려웠던 점 양해 바란다.
이 외의 논문에서는 Sentence Pair + NSP와 Doc Sentence에 관한 내용들도 다뤄져 있는데, 실제 소스로는 확인하기 어려웠던 기능이라, 논문 발췌만 남기도록 하겠다.


2) Dynamic Masking
매 Epoch마다, Masking을 진행하며, 일반 BERT에서 masking을 정해놓는 static masking 기법보다 통상 성능이 더 좋다고 한다. (논문에서는 매 단계마다 15%라고 한다.)

HuggingFace 소스 기반으로라면, BERT로도 Dynamic Masking을 쉽게 적용해서 실험해볼 수 있을 것 같다.
3) Whole Word Masking
이는, 최근버전 Google BERT에도 업데이트 된 내용이다. (파라미터로 넣을 수 있음)
일반 BERT의 경우, '아기상어' 였다면, <mask>,상어 와 같이 구성될 수 있는데, whole_word_mask 처리를 하면, <mask>,<mask>의 형태가 된다.
##이 들어간 경우에(이어질 단어가 있는 경우), 최대한 다 그룹화하여 해당 단어 시퀀스를 각각 <mask>처리를 진행하는 형식으로 소스가 구성되어있다.
때문에, 한국어 같은 경우 샘플들 보면 간혹 앞단어에 표시를 하는 경우가 있는데, 소스를 수정해줘야 할 필요가 있을 것이다.
여기까지 가능하면 소스단으로 확인을 하며, 실제로 ALBERT와 BERT, RoBERTa의 차이점을 확인해보았다.
소스에서 확인해봤을때, HuggingFace의 RoBERTa는 분류문제, QA문제 등에 상관하지 않고, Fine-Tuning Training 과정에서, 뭔가 CLS토큰만의 정보로 진행하는 것처럼 보였다.

BERT 논문에서 보면(아티클 5-2 후반부에도 있음), 적용해야하는 DownStream Task별로, 언제는 sequence_output을 전체사용하고, 언제는 pooled_output을 사용하고 하는 기준이 있었는데, HuggingFace RoBERTa는 일관되게 위의 형태로 되어있어서, 조금 의아했다. (근데 사실 다른 사람들 Fine-Tuning 소스들 보면, 각양각색이라, 이 부분은 실험적으로 해보고 선택해야 할 문제인가 싶기도 하다.) 아마 HuggingFace에서는 전반적으로 위와 같은 형태로 Fine-Tuning을 활용했을때 잘 되니까 저렇게 해두었겠지...
여기까지 봤으면 pre training에서 다룰 수 있는 내용들은 모두 다룬 것 같다. 최근에 MS에서 새로운 BERT를 공개했다고 하는데, 한번 찾아봐야겠다.
다음시간부터는 가능하다면 fine-tuning쪽을 다뤄볼까 하는데, git에 올라와있는 소스들을 기준으로 좀 전반적인 내용을 다뤄야하지 않을까 싶긴하다. (내부에서 개발된 소스를 공유할 수는 없으니까)
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| BERT로 시계열 데이터 분류 Task는 할 수 있을까? (2 - Fine-Tuning을 LSTM으로 many-to-many 연결해보기) (0) | 2022.01.17 |
|---|---|
| BERT로 시계열 데이터 분류 Task는 할 수 있을까? (1 - 근무 시간표 예측?) (0) | 2022.01.16 |
| 딥러닝 TA 모델 - BERT (5-4 - run_pretraining (Optimizer)) (0) | 2022.01.11 |
| 딥러닝 TA 모델 - BERT (5-3 - run_pretraining (NLLloss(masked_lm, NSP))) (0) | 2022.01.10 |
| 딥러닝 TA 모델 - BERT (5-2 - run_pretraining (Transformer Encoder-Pooler)) (0) | 2022.01.08 |




댓글