정말 오랜만에 개발과 관련해서 글을 쓰는 것 같다.
요즘에 음향쪽 STT/TTS 프로젝트를 병렬로 뛰고 있는데, 프로젝트 관리하랴 코드 관리, 내 할당 개발 하려니 정말 정신이 없다.
그 동안 알아낸 점도 많아서 공유하고 싶은 점들이 정말 많은데, 가장 최근에 했는데, 상대적으로 레퍼런스가 없어보이는 kenlm을 사용하고, HuggingFace에서 ~~~ProcessorWithLM의 동작원리와 함께 사용하는 방법을 다뤄보고자 한다.
예시는 일단 Wav2Vec 2.0을 기준으로 사용하려 한다.
KenLM
GitHub - kpu/kenlm: KenLM: Faster and Smaller Language Model Queries
KenLM: Faster and Smaller Language Model Queries. Contribute to kpu/kenlm development by creating an account on GitHub.
github.com
많은 논문들에서 빠르게 n-gram형 nlp 모델을 만들기 위해 주로 사용하는 라이브러리이다.
속도도 빠르고, 사용법도 개발을 할 줄 안다면 비교적 간단하며, 모델의 상세 파라미터를 text 파일 형태로 열어볼 수 있다는 점에서 모델 디버깅도 용이하다고 생각한다.
(설치는 위의 github의 내용을 그대로 따라하면 되므로 따로 설명하진 않겠다.)
n-gram을 지원하는 lm모델 빌더는 많은데, HuggingFace에서 pyctcdecode를 target으로 하여 ProcessWithLM 라이브러리들이 만들어졌고, pyctcdecode에서 기본적으로 kenlm을 target으로 하여 lm을 지원하기에 피차 불가하게 활용하게 되었다.
기능적인 측면에서는 torch decoder에서 제공하는 ctc decoder의 n-gram lm을 사용하는 것도 좋을 것 같다.
N-gram
KenLM을 사용하려는 궁극적인 목표라고 볼 수 있을 것이다. 자기회귀모형에 대해 들어본 적이 있는가?
시계열 (ARIMA)등을 사용해봤으면 한번쯤 들어봤을 법도 한데, 한마디로 과거 N개의 토큰의 상관 영향이 현재 예측을 결정하는 형태를 의미한다.
조건부 확률을 이용해서 구해진다고 하며 통상 TF-IDF를 배우고 나면 바로 다음 챕터에서 다루는 만큼 방식이 비슷하다.
https://heytech.tistory.com/343
[NLP] N-gram 언어 모델의 개념, 종류, 한계점
📚 목차 1. N-gram 개념 2. N-gram 등장 배경 3. N-gram 종류 4. N-gram 기반 단어 예측 5. N-gram의 한계점 1. N-gram 개념 언어 모델(Language Model)은 문장 내 앞서 등장한 단어를 기반으로 이어서 등장할 적..
heytech.tistory.com
설명과 한계점등이 잘 정리되어있으므로 한번 읽어보면 좋을 듯하다.
음향기술에서 대부분의 경우 3~5 gram을 주로 선호하며, 가장 많이 본 형태는 5-gram이다.
위의 사이트에서도 나와있듯이, 띄어쓰기를 기준으로 n-gram을 처리한다.
즉, KenLM을 사용하려면 데이터셋을 우리가 계산하고자하는 n-gram형태만큼 띄어쓰기로 구성해야한다.
데이터 예시 (접은글 펴세요)
모든 문장은 '엔터'로 구분해야한다.
자소로 n-gram을 해보고 싶은 경우
ㅈ ㅏ ㅅ ㅗ ㄹ ㅗ n - g r a m ㅇ ㅡ ㄹ ㅎ ㅐ ㅂ ㅗ ㄱ ㅗ ㅅ ㅣ ㅍ ....
ㄴ ㅏ ㄴ ㅡ ㄴ ㅂ ㅏ ㅂ ㅇ ㅡ ㄹ ㅁ ㅓ ㄱ ㅅ ㅡ ㅂ ㄴ ㅣ ㄷ ㅏ
(자소의 경우 물론 unicode 형태를 사용해야 편리하다.)
음절로 n-gram을 해보고 싶은 경우
음 절 로 n - g r a m 을 해 보 고 싶 은 경 우
단어로 n-gram을 해보고 싶은 경우
음절로 n-gram을 해보고 싶은 경우
개략적인 작업 순서
1. 데이터를 수집한다.
(그냥 평범한 형태의 문장 데이터일 것입니다.)
2. 데이터를 정제한다.
(특수문자 등을 처리하고, 불필요한 문장은 제거하고, 위의 데이터 예시처럼 txt를 만드세요
3. kenlm을 수행한다.
명령어는,
plzlm -o 5 <wefwef.txt > wefwefwef.arpa
띄어쓰기를 모두 완벽히 고려해야하며, 플리즈 lm 이라는 실행명령어로 -o 개만큼의 n-gram을 진행한다.
용량이 크고 느리지만, alphabet.txt를 따로 유지해야할 필요가 없습니다. 1부터 5 gram의 값을 모델이 전부 가지고 있게 되므로.
build_binary wefwefwef.arpa test1.binary
바이너리 파일로 변환합니다 용량이 엄청 줄어들고, 속도가 빨라진다는 이점이 있습니다.
다만, 바이너리 파일을 사용하려면 1-gram alphabet.json파일이 존재해야합니다. (없어도 되지만 성능이 저하됨)
kenlm만 사용한다면 위와 같은 절차를 진행하면 되며, alphabet.json을 만드는 방식은 명령어로 주어지진 않는 것 같았습니다. 현재 예제는 음향모델에서 kenlm을 사용하는 법을 다루고, HuggingFace라는 프레임워크를 사용할 예정이므로,
HuggingFace에서 alphabet.json을 만들 수 있게 지원하기 때문에 꼭 방법을 알 필요는 없어서 넘어가겠습니다.
HuggingFace에서의 ~~~ProcessWithLM
GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, a...
github.com
현재 블로그를 쓰고 있는 22년 08월 15일 기준, pyctcdecoder를 타겟으로 삼고있다.
영어 예제
https://huggingface.co/blog/wav2vec2-with-ngram
Boosting Wav2Vec2 with n-grams in 🤗 Transformers
Boosting Wav2Vec2 with n-grams in 🤗 Transformers Wav2Vec2 is a popular pre-trained model for speech recognition. Released in September 2020 by Meta AI Research, the novel architecture catalyzed progress in self-supervised pretraining for speech recognit
huggingface.co
예제를 확인해보면 사용법은 의외로 간단하다. 위의 방식대로 kenlm 모델을 만들고,
pyctcdecode의 build_ctcdecoder를 이용하여 BeamSearchDecoderCTC 객체를 만들어줍니다.
from pyctcdecode import build_ctcdecoder
decoder = build_ctcdecoder(
labels=list(sorted_vocab_dict.keys()),
kenlm_model_path="5gram_correct.arpa",
)
엄밀히 beam_search(ctc)와 lm은 다른 것입니다.
CTC Loss로 학습된 시간순 예측값에서 가장 확률이 높은 시간순 값을 찾아나가는 디코딩 방식이 BeamSearch이며, 해당 메서드는 때문에 labels (각 시간순에 등장 가능한 정답값. == vocab list)를 필요로 합니다.
kenlm_model_path를 입력하는 순간, BeamSearch 과정 중 lm score를 누적하여 계산하게 되며,
그 밑에 파라미터들은 kenlm을 사용할 경우에 필요한 파라미터로, 중요한 파라미터는 unigrams와 lm_score_boundary가 있습니다. (즉, kenlm_model_path를 넣지 않으면, 일반 BeamSearch만 진행되는 decode가 가능하단 이야기.)
unigrams
모델을 binary로 사용할 경우 필수이며, arpa로 사용할 경우 없어도 됩니다.
alphabet.json으로 불러온 unigram list가 들어가야합니다. alphabet.json을 구성하는 방법은 save_pretraining 메서드로 huggingface에서 자동으로 제공하니 이후에 알아보도록 합시다.
lm_score_boundary
통상 언어모델은 <s>, </s> 가 필요합니다. BOS, EOS 토큰이라고도 불리는데요, 그게 있는 경우 True, 없는경우 False여야 합니다. 음향모델의 경우 BOS, EOS 토큰을 예측하지 않으므로, False로 주는 것이 lm_score가 조금 더 정확하게 나옵니다.
True로 준다고 하더라도, 거의 상대적으로 유사한 비율로 증가, 감소했어서, 안넣어줘도 될까? 싶긴 한데, 일단 저는 False로 주고 합니다.
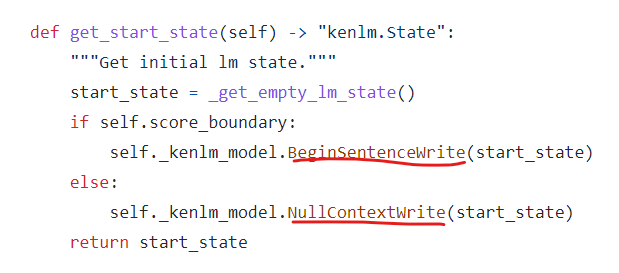
kenlm을 동작시키는 원리 자체가, 직전 state(확률값이라고 볼 수 있겠죠?)만을 저장하면서, 그 이후에 현재 단어가 등장할 확률을 계산하는 형태로 진행이 됩니다. 때문에, 시작 state(확률)을 결정하는 것이 중요할텐데, 그 부분에서 BOS로 시작하는지 어쩌는지를 따져서 state를 계산합니다.
만약, BOS가 없이 score_boundary를 True로 준다한들, 어짜피 비등장에 대한 발산하는 경우가, 최초 BOS에 대한 확률 영향밖에 없을 것이므로, 어떤 값이 들어가도 비율적으로는 동일하다. 라고 생각하지만, 저는 확실히 하기 위해서 False로 줬습니다.
from transformers import Wav2Vec2ProcessorWithLM
processor_with_lm = Wav2Vec2ProcessorWithLM(
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
decoder=decoder
)그 다음 선언된 디코더를 ~~~ProcessorWithLM의 파라미터로 넣어주기만 하면 됩니다.
WithLM이 없는 객체와, 정확하게 decoder밖에 차이가 나지 않으며, 실제 동작 역시, decoder가 추가됨으로써 발생하는 tokenizer에서 수행될 batch_decode, decode에만 영향을 미치므로, 사용법에 큰 어려움은 없습니다.
이전 tokenizer는 나온 logits에서 현재 시점기준 가장 높은 값들만 선택하는 형태였으므로, argmax가 필요합니다.
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
transcription[0].lower()WithLM을 사용한다면, BeamSearch를 이용해서 각 시점별 확률을 계산해야하므로, logits가 그대로 들어가야합니다.
return은 text 객체에 들어있으므로, .text를 이용하여 추출해줍니다.
transcription = processor.batch_decode(logits.numpy()).text
transcription[0].lower()~~~WithLM의 save_pretrained 메서드를 이용해서 선언된 decoder를 저장할 수 있으며,

이 때 vocab.json이 생성되는데 (is_bpe와 vocab이랑 비슷하게 구성된 dict파일 입니다.)
이게 정확히는 vocab.json이 아니고 alphabets.json입니다. (뭔가 버그인지 네이밍이 이상하게 됩니다.)
때문에 save_pretrained를 진행한 후 vocab.json은 alphabets.json으로 변경하고, 본인의 vocab을 찾아다 직접 vocab.json으로 넣어주어야 from_pretrained에서 정상적으로 동작합니다. (안된다고 헤매지 마세요...!)
BeamSearch에서 lm이 어떻게 동작하는가?
GitHub - kensho-technologies/pyctcdecode: A fast and lightweight python-based CTC beam search decoder for speech recognition.
A fast and lightweight python-based CTC beam search decoder for speech recognition. - GitHub - kensho-technologies/pyctcdecode: A fast and lightweight python-based CTC beam search decoder for speec...
github.com
의 _decode_logits 를 보는 것이 빠를 수 있습니다.
결국 batch_decode도, batch처리만 고려할 뿐 동작은 decode로 멀티 프로세싱해서 진행합니다.
decode는 결국 decode_beams 따위를 거쳐서, _decode_logits로 들어가게 되는데, 일반적인 경우, input을 시점별 log_softmax하여 넣게될 것이므로, decode_beams까지의 역할은 중요하지 않습니다.
3중 포문이라 어렵게 보일 수 있는데,
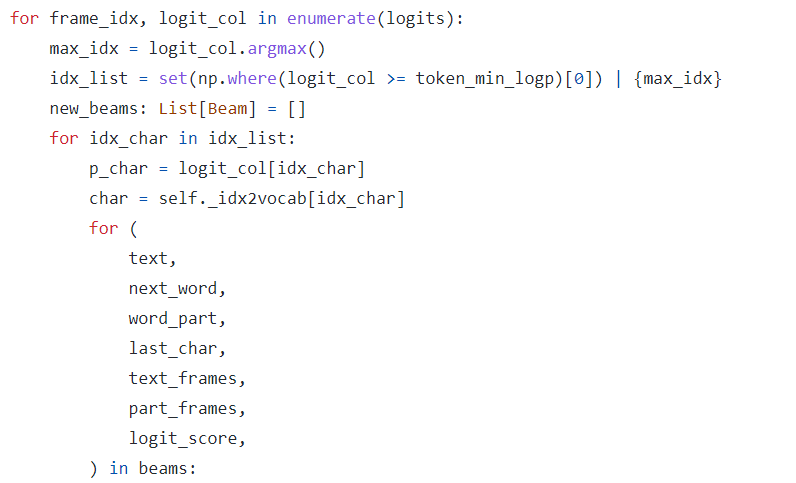
1번째 포문은 logits 전체를 다루는 포문이고
2번째 3번째 포문이 BeamSearch를 진행하는 과정입니다. 각 다음 순서에 대한 곱확률을 계산하고, 경우의 수를 가늠해봐야할 모든 상황을 계산하여 리스트로 저장합니다.
1번째 포문이 끝나기 전, BeamSearch 작업이 모두 완료되어 필요한 경우의 수를 전부 구하고 나면,
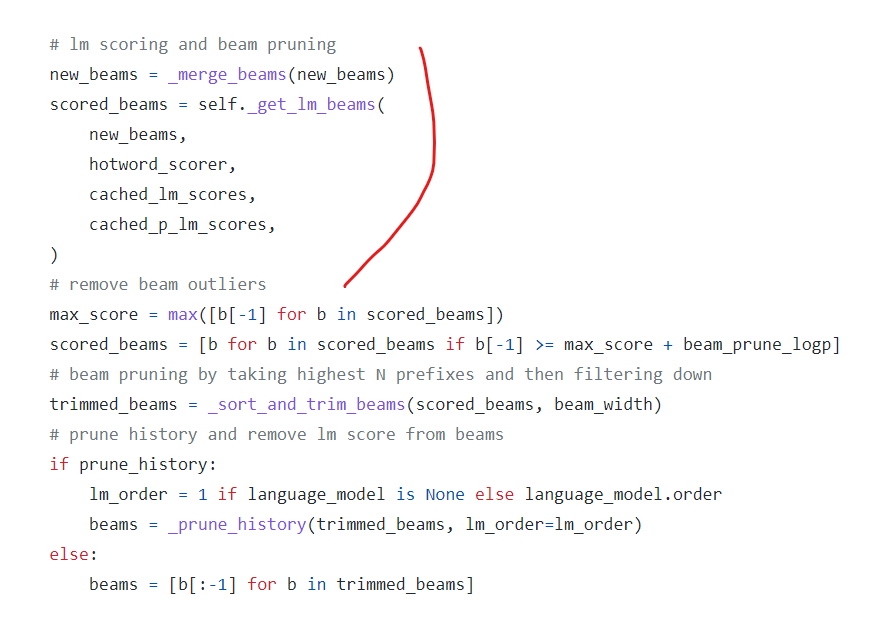
모든 현재시점의 가능한 경우의 수 리스트의 문장에 대한 lm score를 계산하게 됩니다.
1. 경우의 수에 대한 현재시점 모든 등장 가능한 문장을 만듬
2. 모든 문장이 실제 문장으로 등장 가능한 놈일지? lm을 통해 한번 따져봄 -> 현재 위치
3. 최상위 n개의 beam만 계산할 것이므로, sort trim하고, pruning을 진행하는 경우 (특정 확률 미만이면 볼 것도 없어! 잘라버려!) 조건에 따라 pruning 진행하고 다음시점을 계산할 준비를 합니다.
_get_lm_beams에서는 language model이 없으면, 그냥 BeamSearch에서 계산된 곱확률을 return하게 되고,
있을 때만이,
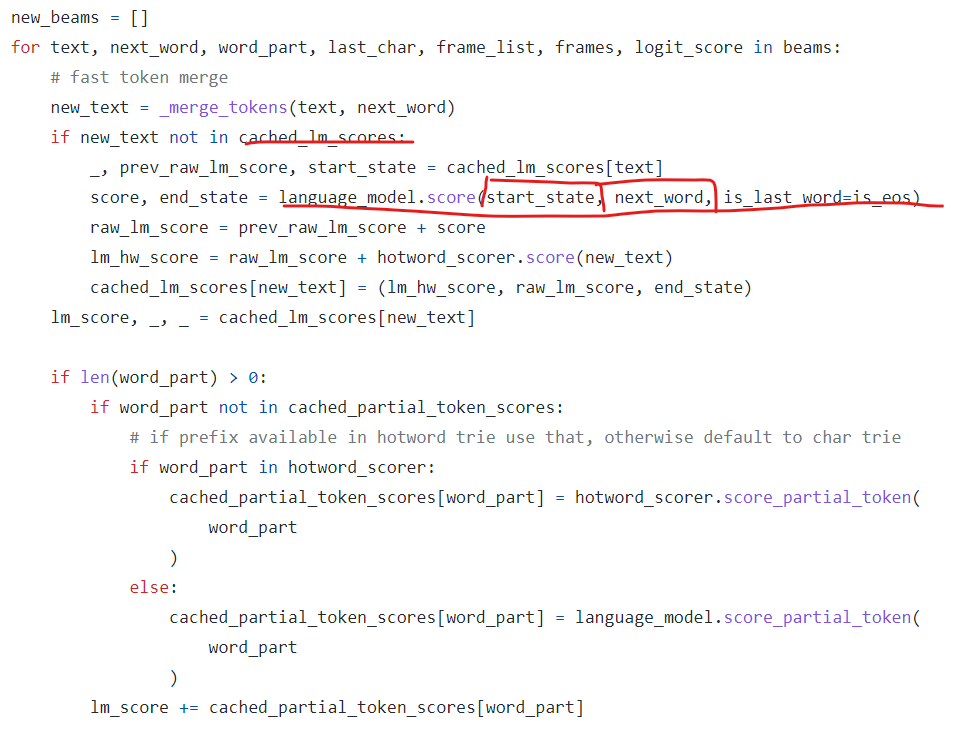
lm score를 계산하게 됩니다. 제가 빨간색으로 표시한 저 구간을 디버깅해보면 lm score를 계산할 수 있으며 각 나오는 확률값은 log softmax값이므로, Numpy.exp()를 통해 실제 확률로 확인해볼 수 있습니다.
대부분의 경우 lm을 잘못 구성해서 의도치 않은 동작이 진행되어 해당 라인의 score의 확률이 매우 낮은 확률로 발산하는 경향을 보였습니다. (-10 미만으로 나옴)
원리는, cached_lm_scores list에 이전 시점에 완성될 수 있는 모든 문장 경우의 수를 넣어놓습니다.
거기에 그 시점에 state도 들어있게 되는데요,
나는 밥을 먹었다. 라는 문장이 있다면,
이전 state는 "" -> 나는 이 나올 확률 이 저장되어 있으며
현재 _get_lm_beams에서는 "" -> 나는 state에서 그 다음 [밥을, 바을, 바ㅂ을, 바블]이 나올 lm_score를 계산해봅니다.
당연 lm이 학습 잘 되었다면, 밥을 이 확률이 가장 높겠죠?
만약에 바블이 선택될 수도 있습니다. 그렇다면 학습된 arpa 파일을 까서, '바블'을 찾아봅니다. '밥을'보다 높습니까?
그러면 바블이 높아서 선택된거니, lm model의 학습 데이터가 잘못되었을 수 있습니다.
뭐 이런 식의 원리로 동작하며, 그 원리를 이용하여 위와 같이 디버깅 해볼 수 있습니다. (참 쉽죠?)
hotword는 어떤 경우 특정 확률을 가중하거나 하고 싶으면 사용할 수 있습니다. 위와 같은 예시에서 딱 쓰기 좋겠네요
'바블이 더 높다고? 아 그냥 밥을에 가중치 더줘야겠다. 하고 hotword에 '밥을'을 넣어주고 점수를 높게 줘야겠네.'
와 같이 사용하세요!!!

process에서 batch_decode를 사용할땐 위와 같이 활용하세요. beam_width등을 넣을 수 있고,
그리고 build_decoder에서 실수로 lm_score_boundary를 True로 줬다고 하더라도, batch_decode에서 False를 주면 init_parameter해서 batch_decode의 파라미터로 덮어쓰고 사용합니다. (물론 일관되게 넣는게 맞겠지만요)
KenLM에 대해서, 그리고 HuggingFace에서의 KenLM 사용법에 대해 알아봤습니다.
사용법은 어찌보면 쉬울 수도 있는데, 때문에 노하우가 중요합니다.
일단 영어는 알파벳 -> 단어 -> 문장 입니다.
한국어는 자소 -> 음절 -> 단어 -> 문장 입니다.
알파벳은 유니코드로 쪼갤 필요가 없습니다.
한국어는 자소의 경우 유니코드로 쪼개야됩니다.
자소로 n-gram은 불가할까요? (참고로 next_word의 Input은 word입니다.)
그렇다면 word는 유니코드 word일까요? 일반 텍스트 word일까요?
본인의 데이터셋을 어떻게 구성하느냐에 따라 위의 고민들을 해봐야 할 수도, 하지 않아도 될 수도 있습니다.
물론 디버깅을 잘하신다면 하나하나 찍어보면서 가늠해보는 것도 방법이겠죠.
저는 참고로 자소를 이용하여 n-gram으로 모델을 개선하는데 성공하였고, 약 1.2%p 정확도가 좋아지는 효과를 보았으며, 기타 부수적인 효과도 봤습니다. (1.2%p 가 작아보일 수 있는데, 20% 남짓에서 10%대로 진입하느냐 마느냐의 문제입니다.)
즉, 자소로 n-gram은 분명히 가능하고, 효과가 있습니다. 저도 과거에서부터 잘 안된다고 들어왔고, 실제로 막연하게 해봤을때도 잘 안됐어서, 정말 안되는줄만 알았는데, 하나하나 톺아보다보니 안될 이유가 없더군요...
안된다고 생각하지 마시고 하나하나 차근차근 고민해보시기 바랍니다. 분명 가능하니까요...!!
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| HuggingFace Datasets Audio에서 이제 pcm을 지원합니다. (0) | 2022.08.15 |
|---|---|
| BERT로 시계열 데이터 분류 Task는 할 수 있을까? (2 - Fine-Tuning을 LSTM으로 many-to-many 연결해보기) (0) | 2022.01.17 |
| BERT로 시계열 데이터 분류 Task는 할 수 있을까? (1 - 근무 시간표 예측?) (0) | 2022.01.16 |
| 딥러닝 TA 모델 - BERT (6 - BERT의 파생 (ALBERT, RoBERTa)) (0) | 2022.01.14 |
| 딥러닝 TA 모델 - BERT (5-4 - run_pretraining (Optimizer)) (0) | 2022.01.11 |




댓글