딥러닝 TA 모델 - BERT (5-4 - run_pretraining (Optimizer))
2022.01.10 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (5-3 - run_pretraining (NLLloss(masked_lm, NSP)))
딥러닝 TA 모델 - BERT (5-3 - run_pretraining (NLLloss(masked_lm, NSP)))
2022.01.08 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (5-2 - run_pretraining (Transformer Encoder-Pooler)) 딥러닝 TA 모델 - BERT (5-2 - run_pretraining (Transformer Encoder-Pooler)) 20..
shyu0522.tistory.com
에서 이어집니다.
이전 시간까지는 뭔가 현실에서 비유해볼 수 있을 법한 프로세스들을 다루었다. (채점까지 했으니까...ㅎㅎ)
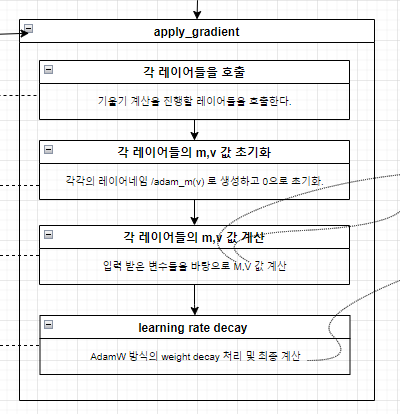
이번 시간에는, 실제로 딥러닝 관점에서, 채점된거로 학습을 하기위해서 어떤 Gradient Optimize 과정들이 진행되는지 알아보자. (사실 프로세스는 동일하고, 사용되는 옵티마이저와, 적용된 기술들 위주로 서술하겠다.)
옵티마이저 과정에서는, 크게 2가지가 변동성을 가지고 변화된다.
1) learning_rate
2) optimizer's update value
1. Learning Rate

polynomial_decay를 이용하여 일단 선형 감소 시키는데, 그 기준에 대해서는 num_warmup_steps가 값이 있을때,
Default 기준 10000 에폭까지 현재 진행상황 대비 비율 균등하게 낮춘다.
낮추다가 10000에폭까지 진행되면 설정한 learning_rate로 동작한다. (default 0.0001)

초반에 큰 Epoch으로 진행하면, 수렴이 잘 안되어, 낮은 값에서 시작하여 큰 값을 선택하도록 한다.
2. Optimizer's update value
옵티마이저는 일단 'AdamWeightDecay'를 사용한다. (Adam에서 WeightDecay를 적용한 방식이고, 논문에서도 상세하게 어떤값들로 decay 되는지 설명 되어있다.)
Weight Decay는 말그대로 가중치 감쇠이다. 어떻게 감쇠를 시키는가 하면, 패널티를 줘서 감쇠 시킨다.
패널티 하면 흔히 생각나는 L1, L2/라쏘, 릿지가 생각날텐데, Weight에다가 L1패널티 혹은 L2패널티를 줘서 감쇠시킨다.
얻을 수 있는 효과로는, 가중치가 감쇠되므로, 오버피팅이 될 가능성이 낮아질 것이다.
이는 사실, 오버피팅이 발생할 수 있는 딥러닝 Task에서는 어디든지 적용해볼 수 있는 부분이니 잘 참고하길 바란다.

현재 BERT에서 적용된 방식은, 일단 Adam Optimizer를 구해놓고,
[비전공자용] [Python] 모멘텀, AdaGrad, Adam 최적화기법
이번 포스트에서는 모멘텀, AdaGrd, Adam 최적화 기법에 대해 상세히 알아볼 겁니다. 1. 모멘텀 Momentum 모멘텀은 운동량을 뜻하는 단어로, 신경망에서의 모멘텀 기법은 아래 수식과 같이 표현할 수
huangdi.tistory.com
거기서 update되어야하는 기울기 값에, weight_decay를 적용하는 형태로 반영하였다.
아담을 구하고,

그 값에 weight decay 방식 적용

마지막으로 위에서 적용된 learning_rate와 혼합하여 실제로 기울기가 변화되게 된다.
keras를 쓰다보면, optimizer에서 learning_rate를 조정할때 LearningRateScheduler 같은 콜백함수를 정의해서 사용하는 경우가 일반적이었는데 (그때는 거의 그냥 단순 선형감소 등을 이용했었다.)
위와 같은 방법들을 참고해서 적용해보는 것이 더 유의미할 수 있어 보이므로, 꼭 한번 확인해보고 숙지해두길 바란다.
다음 시간에는, 진행중에 관심을 가졌었던, BERT의 파생들에 대해서 간략하게 알아보도록 하겠다. (AlBERT, RoBERTa)
그럼 이만!