딥러닝 TA 모델 - BERT (3 - data_preprocess, BPE)
2022.01.05 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (2 - Attention)
딥러닝 TA 모델 - BERT (2 - Attention)
2021.11.21 - [딥러닝으로 하루하루 씹어먹기] - 딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적) 딥러닝 TA 모델 - BERT (1 - 기초. 행렬과 벡터, 내적) 이전 시간으로, STT(ESPNet)를 어느정도 시작부터..
shyu0522.tistory.com
여기서 이어집니다.
사실 BERT는 Attention은 그냥 기본이 되는 이야기이고, Attention 전/후로 Data를 학습시키기 좋은 형태로 변환하는 과정과, 그 것을 역전파로 학습시키기 위한 loss를 산정하는 과정에서의 역할이 더 중요하다고 할 수 있겠다. (사실상 학습 몸통은 Transformer기 때문에 특별할게 없기 때문에.)
지난 시간까지의, Attention은 그냥 내가 업무에 적용시켜보면서 흥미로운 부분도 많았고, 관심도 많이 가던 기술이었기에 좀 구체적으로 설명을 했을 뿐이고, 이번 시간부터는 실제로 BERT의 학습과정을 Pre-Training 부터 나아가보고자 한다.
일단 내가 설명하고자 하는 기본 골조는,
https://github.com/google-research/bert
GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
TensorFlow code and pre-trained models for BERT. Contribute to google-research/bert development by creating an account on GitHub.
github.com
에서의 pre-training 과정을 뜯어보면서, 작성한 내용이며,
https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=164
자연어 언어모델 ‘BERT’ | T아카데미 온라인강의
1. 자연어의 개념과 다양한 언어모델에 대해 알아본다. 2. BERT 모델의 개념 및 메커니즘에 대해 이해하고, 한국어의 BERT 학습 방법에 대해 알아보다.
tacademy.skplanet.com
의 강의가 도움이 매우 많이 됐음을 먼저 밝힌다.
(최초의 실습은 해당 강의의 소스를 그대로 활용하여 사용했었습니다.)
소스에 주석도 많고, 이것저것 테스트 소스들도 있긴 한데, 아직 정리가 다 되진 않아서, 전부다 바로 공개는 안될 것 같고, 하나하나 아티클이 정리되는데로 소스가 정리가 다 되면 git에 하나씩 올릴 예정이다.
순서대로 하나씩 보자
1. Data 준비 (크롤링 등 알아서)
일단 데이터가 필요할 것이다. 데이터는 필자는 일단 위키피디아 크롤링 데이터를 기준으로 설명하겠다.

pre-training을 진행하기 위해서는, 우선 2가지 Data가 필요하다.
1) vocab을 만들 Text
2) 실제 Pre training에서 masked, next sentense pred를 진행할 Target Text
사실상 BERT가 Pre-Traning과 Fine-Tunning과정이 중요하다고 생각들겠지만, 사실 그렇지않다.
가장 중요하면서도, 기술적으로 핵심적인 부분은 data_preprocess (make_vocab) 부분이라고 생각한다.
data_preprocess는 마치, 우리가 영어 공부를 하기전에, 알파벳과 기본적인 단어책을 사는 과정과 동일하다.
같은 알파벳으로 학습을 한다지만, 누구는 영국식 단어책을 가지고 공부하고, 누구는 미국식 단어책을 가지고 공부하거나, (영국은 화장실이 toilet이지만 미국은 restroom이라고 한다. 그러면 실제로 소통간 문맥 이해가 잘 안될 수 있다.)
만약에 단어책이 출력에 오류가 있어서, rest room과 같은 형태로 출력된거로만 공부한다면, 우리는 영영 restroom이라는 단어를 모르게 될 수도 있는 것이다.
우리나라의 경우, '아버지 가방에 들어가신다.' 와 '아버지가 방에 들어가신다.'와 같이 단어의 구성을 '가방'으로 하느냐 '방'으로 하느냐 띄어쓰기 차이에서도 의미적 모호성이 발생할 수 있으므로, 단어의 전처리를 얼마나 잘 하느냐가 사실 BERT를 얼마나 잘 학습시킬 수 있느냐의 차이로 생각되기도 한다.
(실제로, 특정 고객사의 상품명이라거나, 고객의 이름이 순한국말 특이한 이름인 경우, 새로운 상품이 추가된 경우 등 모델이 실무를 하다보면 모델이 겪어보지 못한 Case가 등장하거나, 그런 Case가 Inference 단계에서 출력값에 영향을 미치는 경우 골치아파진다.)
사실 data_preprocess는 단어를 쪼개는 과정 자체를, 어느정도 레퍼런스 있는 방법으로 자동화 하기위해서 있는 소스이며, 만약 현업에서 아 우리는 이런 단어만 있어도 충분히 할 수 있다! 라고 하면, 그냥 vocab.list를 직접 구축하는 것이 나을 수도 있겠다는 판단이다.
일단 현재 아티클에서는 구글의 기술에 기반하도록 하였으니, BPE를 기반으로 설명하도록 하겠으며, git에 소스는 올라가 있으므로, 스크린샷으로 찍어서 설명하도록 하겠다.
또한, 테스트를 위해서 작성해놨던 소스블락은 넘어가도록 하겠으니, 해당 아티클에 없는 소스 블락은, 테스트용이었다고 생각하면 된다.
https://github.com/YooSungHyun/deep-learning/tree/master/BERT_GYM
data_preprocess.ipynb
일단 띄어쓰기만으로 구분하기 전에, 형태소 처리를 한 데이터로 구분을 하면 어떨까? 싶어서 접근해본 방법이다.

여기서의 형태소 처리는, 단순하게 WordPiece를 하는 기준으로 삼기 위함일뿐, 어떤 수려한 이유가 존재하는 것이 아니기 때문에, 사실상 BPE를 그냥 진행해버리면, 크게 할 이유가 없는 소스이기는 하다.
약간은 의미가 있을 수도 있긴 한데, 그건 뒤에서 구체적으로 설명해주도록 하겠다.
test는 BPE가 어떻게 진행되는건지 빨리빨리 보고싶어서, small.txt로 그냥 퀵하게 돌려보기 위함이다.
여기서는 Mecab이 활용되지 않으니, 그냥 단순 BPE가 진행된다고 보면 된다.
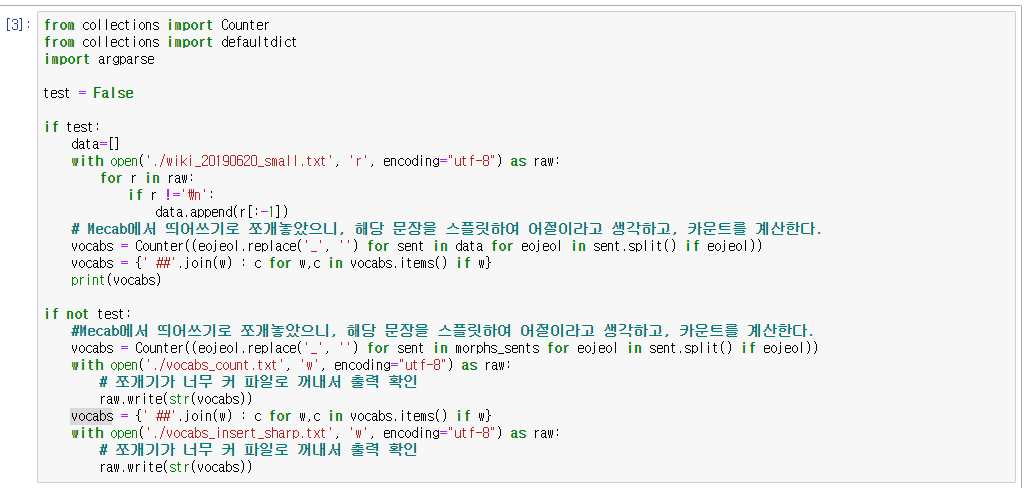
if not test: 절에서가 진짜라고 볼 수 있는데,
BERT는 Wordpiece로 쪼개진(띄어쓰기로 쪼개진) 문자에 BPE를 진행하기 때문에, 일단은 Wordpiece 단위로 표현하고자 한다.
Wordpiece 모델도 Count를 사용하기 때문에, Dict가 해당 소스와 같이 구성되지만, 우리는 어짜피 Byte Pair Count에 의존할 것이므로, BERT에서 크게 중요한 값은 아니다.
Wordpiece의 띄어쓰기 단위로 분리한 다음, 맨 처음이 아닌 단어에는 '##'을 붙혀준다.
실제로 bi-gram(앞뒤글자) byte pair count를 체크하며(get_stats), Count가 가장 많은 글자는 set로 묶는다.(merge_vocab)
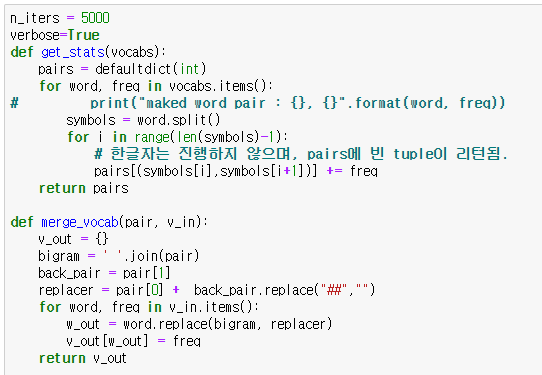
n_iters를 결정한만큼, 반복하며 set를 찾아나간다. 위에 주석('______의견확인필요') 부분은, 1글자씩 쪼갤 것이며, 10번 반복을 한다면, 최대 10번 합쳐질 수 있을 것 이므로, 1글자가 10번 합쳐져봐야 최대 len = 10일 것이라는 내 가정이다.
만약에 무척 긴 set가 있는 도메인이라면, 사전을 만들때 n_iters 설정을 생각 잘 해서 반영해야된다는 말이다. (아니면 run_pretraining 전에 vocab.list에 직접 넣던가.)

이렇게 하면 우리는 bi-gram pair를 count 기준으로 조사한, 가장 단어스러운 언어 학습용 단어책(units)을 만들 수 있다.
어떤가 만족스러운가?
잘 만들어진 단어책을 이제 제본 할 준비를 하자. (vocab.list 로 파일 write)
나는 막 테스트하면서 해서, 파일명이 좀 엉망이다.(sample_nor~~~.txt) 통상 실무에서는 vocab.list 따위의 파일로 가장 많이 쓴다.

여기까지 진행되면 BERT에서 개인적으로 본인이 가장 중요하게 생각하는, vocab.list가 완성된다!
f.write에 대한 설명.
BERT에서 VOCAB을 생성하는데 있어, 기본적으로 Speacial Tokens는,
PAD = "[PAD]"
EOS = "[EOS]"
UNK = "[UNK]"
CLS = "[CLS]"
SEP = "[SEP]"
MASK = "[MASK]"
RESERVED_TOKENS = [PAD, EOS, UNK, CLS, SEP, MASK]
위와 같은 순서로 쓰인다. pad는 전반적으로 0로 사용되는게 일반적이나, 나머지에 대한 순서들은 그냥 적당히 사용하는 것 같다. pad는 0으로 사용되는데 있어서, 어떤 모델에서도 pad는 학습이 되어야 하면 안되므로 가급적이면 0으로 표현하는 것 같다.
통상 index로 vector seq를 할당받아서 자동으로 pad는 0이 된다.
TensorFlow에서 권장하는 값은 pad는 0 cls는 101 sep는 102를 권장한다.
위의 전 과정을 FlowChart로 그려보면 이렇다. (data_preprocess.py의 흐름)
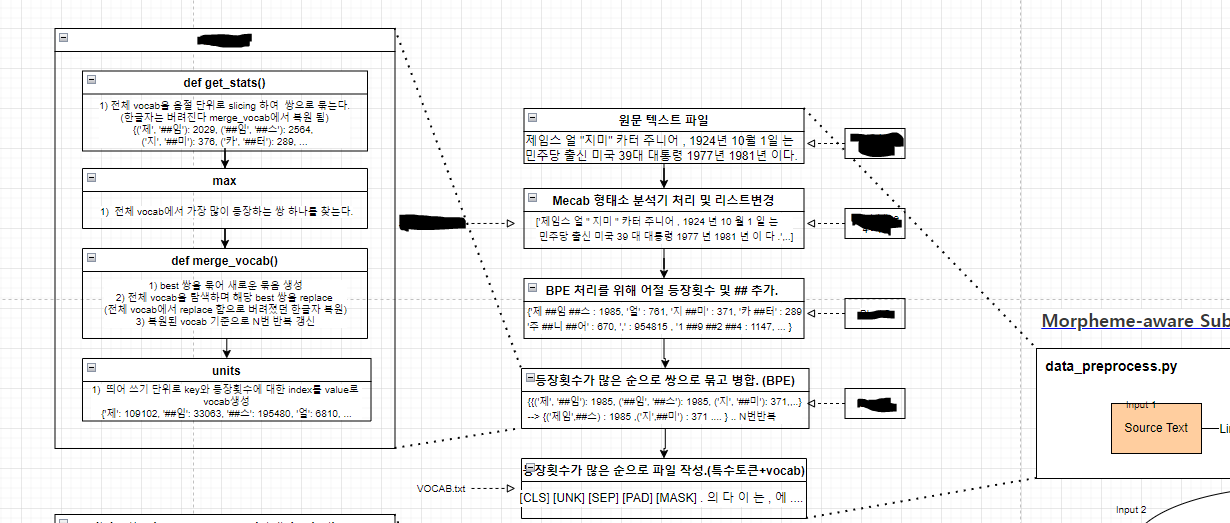
몇 가지 추가적인 이야기들. (BPE를 조금 더 수려하게 이해해봅시다.)
1.
우리는 위에서 두가지 Count를 보았다. (Wordpiece 기준, BPE 기준)
두개의 Count는 같은가? 다른가?
정답은. 다르다. (하지만 운좋게 같을 수도 있다.)
예시 데이터)
제임스 얼 카터
제임슨은 맛있다
WordPiece의 Counter Count는, 띄어쓰기로 구분된 단어의 개수이다.
제임스/얼/카터
제임슨은/맛있다
=> 모두 카운트 각각 1
BPE는 BI-Gram Frequency로 산정된다.
제 #임, 임 #스, 얼, 카 #터
제 #임, 임 #슨, 슨 #은, 맛 #있, 있 #다
=> '제 #임'은 2회, 나머지는 전부 1회 (그래서 '제임'이 n_iters=1에 합쳐지겠지?)
물론 bpe가 무척 많이 돌면서 '제임 #스'가 합쳐질 Case가 발생한다면,
예시 데이터)
제임스 얼 카터
제임슨은 맛있다
제임스 본드는 멋있다
'제임 #스'는, 당장에 n_iters=2에 합쳐질 것이며(제임 #스, 본 #드), 결국 '제임스'는 (제임스 얼 카터, 제임스 본드)로 2회 등장 가능하니, WordPiece의 Count와 BPE의 Frequency가 같아질 수도 있긴하다.
이로써 유추해볼 수 있는 사실은, BPE가 많은 횟수를 진행하면서, 완벽하게 단어셋으로 구성되는 경우일수록 WordPiece Count==BPE Frequency가 될 확률이 높아질 것으로 생각해볼 수 있다. 그렇지 않으면 다를 확률이 더 높겠고
2.
띄어쓰기가 WordPiece던, BPE던 비교대상을 구분짓는 핵심 기준이기에, 띄어쓰기를 잘 처리해야한다!
띄어쓰기로 구분되어 진행된 BPE는 한 토큰이 완성되면, 더 이상 BPE로 쓰이지 않는다.
['제임스','본드']라면,
'제 ##임 ##스' -> '제임스'가 완성되면 뒤에 의미가 있을 법한 이어볼 단어가 없으므로 끝.
'본 ##드' -> 본드도 결국 그냥 본드 따로 처리됨
['제임스본드']였다면?
'제 ##임 ##스 ##본 ##드' -> 본드까지 있었다면, 본드도 '제임스''본'이 더 의미있을지, '제임스''본드'가 더 의미있을지 count로 세보아할 것이다. (물론 위의 케이스로써는 '제임스'만 합쳐지겠지만)
이런 이유에서 내가 잠깐 삽질했던 케이스인데, 소스를 잘못짜서 실수로 띄어쓰기를 넣었다?
=> 에러도 나지않는데 vocab.list에서 절대 보이지 않는, '이게 왜 안 섞이지?' Case 발생함. 이거 결국 디버그해서 찾았다.
이게 상황에 따라 이슈가 될 수도 아닐 수도 있는데, '제임스' '본드' 가 되던, '제임스 본드'가 되던, 결국에 모델이 어디에 유사성을 가지고 학습하냐에 따라 달라질 수 있는 문제이긴한데, 만약 데이터셋에서 '본드'가 '오공'이랑 더 연관선이 훨씬 높게 나와버리면, '제임스' '본드'의 인식률이 다소 떨어지는 경향을 보일 수 있다. (물론 이는 Data 편중에 의한 오버피팅 문제로 접근할 수도 있겠지만.)
내가 얘기하고자 하는 바는, 데이터를 학습시키기 전에, 무거운 모델로 무거운 데이터를 학습시키면 무지성으로 그냥 잘 될거라고 생각하는 경향도 있는 것 같은데, 상당히 조심해야될 접근방법이라는 점이다. 데이터를 잘 처리하고 나중에 고생 덜 할지, 데이터를 무지성으로 넣고 정작 training 과정에서 고통받을지는 본인 선택이니까.
3.
한 글자인 경우에는, 우선 bpe 대상으로 사용되지 않는다!
제임스 얼 카터의 '얼'은 1단어이므로, WordPiece Count에서는 '얼'로 된 단일 문자열은 전부 숫자가 세어진다.
Bi-Gram화 된 데이터에서는, Bi-Gram으로 표현할 수 없으면 진행을 안하기때문에, Frequency가 아예 생성되지 않는다.

만약에, '얼'만 있으면 해당 '얼'이 등장한 count만 frequency가 된다. (wordpiece count = bpe frequency)
근데, '얼 #음', '얼 #핏' 등의 얼로 시작하는 단어가 많아지면, BPE에서 결국 '얼'은 동일하게 들어있는 set로 판단되어 BPE 경합에 사용된다.
이게 왜 그러냐면, 소스상에서 개수가 모두 중복되었을때, 조건이 없다. 때문에,

물론 이도 기준을 잡아서 우선순위를 정하거나 하는 식으로 소스를 수정하면 되는데, 일단 지금 형태로써는,
반복수가 적으면, word count의 갯수에 집약되게 되는데, 예를들어, ‘얼’이 700개, ‘얼 #핏’이 50개 있는데, iter를 매우 짧게 해버리면, 당연히 freq적으로 더 많이 등장한 ‘얼’에 합쳐져서, ‘얼’, ‘#핏’의 형태로 쪼개지게 된다.
반복수가 높으면 최대한 단어로 만드려고해서, 한 글자짜리들이 없어져, OOV가능성이 올라갈 것 같고, 반복수가 낮으면 최대한 쪼개려고 해서, 정상적인 단어 구성이 힘들지 않을까 싶다.
이 부분은 실제로 형태소처리기를 사용하여 bpe할때 테스트하고 넘어가야할 부분으로 사료된다.
4.
Mecab하고 BPE하는 것은 의미가 없을까?
그래서 지금 내가 쪼개놓은 형태의 mecab은 그나마, 조사(은는이가) 같은 데이터들은 한글자로 쪼개지므로, 단순 띄어쓰기로 쪼갰을 때 보다는, 조사가 bpe 결과로 남아있을 가능성이 조금이라도 더 높다.
다만 이게 조사인지, 아니면 word count 가중치로 인해 단어에서 떨어져나온 것인지 알 수 없다는 단점이 있다. 이 부분을 해소하기 위해서 ‘단어/형태소’ 처리가 필요하지 않을까 사료된다.
다만, 형태소를 활용하려면, 만약에 pred가 형태소까지 처리된 값으로 나온다면, 미리 원문에서의 포지션을 기억해놓는다던지 해서, 다시 데이터를 사람이 인지 가능하게 역변환하는 방식을 고민해봐야한다.)
내가 생각한 관점이 또한, 최근에 많이 사용되는 부분으로, 유용한 레퍼런스 하나 링크 남긴다.
[NLP 논문 리뷰] An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks
Paper Info
cpm0722.github.io
이번에는 단어책만 만들었으니, 다음 시간에는, 해당 단어책이랑 묶어서 볼만한 실제 교육을 위한 문제집을 만들어보도록 하겠다.
(create_pretraining_data.py)