조건부 확률부터 마르코프까지 - 5-5) HMM Decoding Task (Viterbi)
2022.01.03 - [Python과 확률] - 조건부 확률부터 마르코프까지 - 5-4) HMM Learning Task (Training)
조건부 확률부터 마르코프까지 - 5-4) HMM Learning Task (Training)
2022.01.02 - [Python과 확률] - 조건부 확률부터 마르코프까지 - 5-3) HMM Backward Algorithm 조건부 확률부터 마르코프까지 - 5-3) HMM Backward Algorithm 2021.12.27 - [Python과 확률] - 조건부 확률부터 마..
shyu0522.tistory.com
에서 이어집니다.
Decoding은 내용자체가 쉬워 제 아티클 만으로도 이해되실 수 있는데, 혹시 몰라서 추가해놓습니다.
https://www.youtube.com/watch?v=P02Lws57gqM
이제 모델을 학습할 줄도 안다면, 실제로 우리가 진짜 알고자 하던, 대망의 Hidden States를 예측할 수 있어야 한다.

Evaluation에서 우리는, 관측 시퀀스에 따른 아이스크림을 먹었을 확률이 궁금했다. 때문에 어떤 상태(case)라도 누락되면, 확률적으로 논리가 부족하게 된다. (다 더해줘야 한다.)
예는 매우 간소화 되긴 했지만, 만약에, 친구와 해외 축구 점수 내기를 한다고 할때,
성현이가, "야 손흥민 안나오면, 토트넘 무조건 지지" 라고 얘기했을때
동숙이가, "야 손흥민 나오고도, 질 확률은 생각 안함?" 이라고 얘기하지 않겠는가?
때문에 더해주는 관점이라고 보면 되겠다. (모든 경우의 수에서 확률을 전부 고려해봐야하니까!)
여기서 논리를 그나마라도 강하게 가져갈 요량이었다면,
"야 손흥민 내가 나올때 질때 지는거 다 아는데, 내가 봤을때 오늘 짐" 이라고 얘기하는게 차라리 나았을 수도 있다!
하지만 Decoding은 얘기가 다르다. Hidden States가 알고 싶은 것이다..!
우리는 손흥민의 이전 출전이력에 따른 토트넘 승패확률을 알고 있다. (HMM(토트넘 손흥민*))
그러면 다음경기에서 손흥민이 안 나왔을때, 질 확률이 더 높을까? 이길 확률이 더 높을까?
높은 확률을 찾고 싶지 않은가...!!!??? 때문에 Max를 해줘야 하는 것이다.
(참고로, 출전여부는 관측이겠고, 승패여부는 히든이라고 한다면 말이다....)
사실상 모든 조건 경우에 따른 높은 확률을 선택하는 문제이기 때문에, 통계적 수식은 Forward 알고리즘과 완전히 동일하며, 단지 Max를 취한다는 점만 유일하게 다르다.
2021.12.27 - [Python과 확률] - 조건부 확률부터 마르코프까지 - 5-2) HMM Forward Algorithm
조건부 확률부터 마르코프까지 - 5-2) HMM Forward Algorithm
2021.12.31 - [분류 전체보기] - 조건부 확률부터 마르코프까지 - 5-1) HMM 기초 조건부 확률부터 마르코프까지 - 5-1) HMM 기초 2021.12.25 - [Python과 확률] - 조건부 확률부터 마르코프까지 - 4) 마르코프 체..
shyu0522.tistory.com

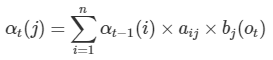
소스는 두 곳에 전부 업데이트 해두었다.
완전한 샘플 연습을 위한
https://github.com/YooSungHyun/probability/blob/main/HMM_practice.ipynb
GitHub - YooSungHyun/probability: Independent, Markov Property, Chain, HMM and BEYOND!🚀
Independent, Markov Property, Chain, HMM and BEYOND!🚀 - GitHub - YooSungHyun/probability: Independent, Markov Property, Chain, HMM and BEYOND!🚀
github.com
import collections
from typing import Tuple
def decoding(start_keyword:str, transition_dict:collections.defaultdict(dict), emission_key:list, observation_list:list) -> Tuple[list, list]:
# dp[상태][관측값(T)]
dp = list()
print('Viterbi Algo')
# start로부터 첫번째 dp를 결정짓기 위함 (initialize)
tmp = list()
for i in emission_key:
dp.append([transition_dict[i][start_keyword]*emission_dict[observation_list[0]][i]])
for observ in range(1,len(observation_list)):
for to_emi in emission_key:
tmp = list()
for from_emi in emission_key:
tmp.append(dp[emission_key.index(from_emi)][observ-1]*transition_dict[to_emi][from_emi]*emission_dict[observation_list[observ]][to_emi])
dp[emission_key.index(to_emi)].append(max(tmp))
hidden_states_list = list()
for i in zip(*dp):
hidden_states_list.append((emission_key[i.index(max(i))],max(i)))
return dp, hidden_states_list
다른 사람들 소스를 보면 성능을 위해서 조금 소스를 개선하거나 한 부분들도 있던데, 나는 Forward를 최대한 '그대로' 사용하였다. 그래야 지식습득 면에서 기승전결이 맞아 떨어지기 때문이다.
max(tmp)를 하여서, 실제로 리스트에 max를 해서 사용하는 것까지 비슷하게 처리하였다.
다만, forward나 backward는 output이 dict 형태지만, viterbi는 2차원 array이다.
(max를 내장함수만 사용하여, 효과적으로 2차원 배열에서 처리하기 위함)
설명과 다른 유일한 부분이 있다면, 원래 같으면 end부터 차근차근 올라와서 Array를 Reverse해야하나, 나는 이미 dp에 차곡차곡 잘 쌓아놓은 셈이 되기때문에, 그냥 정방으로 for문 돌리면서 max만 담아내게 된다.
해당 소스는 기존에 만들어놨던 HMM_ysh.py에 추가된 내용이다.
https://github.com/YooSungHyun/probability/blob/main/HMM_ysh.py
GitHub - YooSungHyun/probability: Independent, Markov Property, Chain, HMM and BEYOND!🚀
Independent, Markov Property, Chain, HMM and BEYOND!🚀 - GitHub - YooSungHyun/probability: Independent, Markov Property, Chain, HMM and BEYOND!🚀
github.com

위에 작성했던 것과 사실상 동일하나, class 변수를 사용하기 위한 변화만 줬다.
실제로 HMM_ysh_test.ipynb 파일이나, HMM_practice.ipynb 파일로 테스트 해보면,

꽤나 그럴싸하게 곧 잘 나온다.
이리하여, HMM를 다룰 수 있는 기본소양과, 활용할 수 있는 준비는 모두 마쳤다고 볼 수 있다.
직전회사를 다닐때 실제로 실무에서 활용하긴 했는데, 뭐랄까, 고객에게서 CS가 들어오면 대응하기가 약간 까다로웠다.
(아 이게 이렇고, 저렇고, 이랬을때 확률 중에 최대를 선택하니 어쩌니...하면 물론 고객이 들으려고도 안하니까...ㅋㅋ)
차라리 디시전 트리 같은 회귀모델을 썼는게 훨씬 나았으려나 싶을 정도로....
일단 다시금 한번 되짚어보는 시간으로 매우 알찼던 것 같고, 다음 시간에는
미뤄놨던 연속형 변수에 대한 나이브베이즈 분류 처리나, HMM을 확장시켜서 사내 데이터로 돌려볼까 싶기도 하고, 어쩌면 CNN이나 LSTM 같은 딥러닝 아키텍쳐를 내장함수로 짜본다거나....
뭐 시간과 느낌이 가는데로 저 중 하나를 선택해서 진행할 듯 싶다.
글씨가 많은 편이라, 이해하기 좋은 아티클을 썼는지 항상 고민인데, 그래도 HMM 아티클은 올리자마자 반응이 좋아서 상당히 뿌듯하긴하다...!
그리고 놓친 부분인데,
해당 아티클을 읽으시는 많은 분들 새해 복 많이 받으시고, 올 한해도 건강하게, 제 블로그에서 얻어가시려는 목적보다 훨씬 더 많은 성취를 이루시기를 기원합니다.