BERT 관련 프로젝트를 진행하면서 쓰려니, 왔다갔다 정신이 없다...ㅋㅋ
그래도 시간이 좀 되는거 같아 바로 이어서 가보도록 하자.
2021.10.21 - [논문으로 현업 씹어먹기] - 딥러닝 STT 모델 - ESPNet (3 - 환경구성만 1 Article)
딥러닝 STT 모델 - ESPNet (3 - 환경구성만 1 Article)
오랜만에 블로그를 작성하는 것 같다. 최근에 서비스에 STT 모델을 학습시켜 사용해야하는 Task 때문에 정신이 없었다. 또한, 콜 예측 관련된 Task는 그냥 Base로 깔고가는 편이라, 너무 정신이 없었
shyu0522.tistory.com
서론
지난 시간에서 다뤘던 3가지 이야기들은,
1. ESPNet과 Kaldi의 설치 (Kaldi가 곁다리로 들어가면서 매우 복잡해진다.)
2. Kaldi에 대한 기본적인 이해
3. ESPNet을 사용하기 위한 최소 조건 규격들 (폴더구조, 데이터의 형식 등)
에 대한 이야기들이었다. (4번 5번은 도메인 지식으로, 필요한 부분에서 추가적으로 설명하기로 했었다.)
이제 환경구성(espnet설치, kaldi설치, 폴더 구조 설정, 학습용 스크립트 작성) 및
데이터의 준비(utt2spk, spk2utt, wav.scp, text)가 다 되었다는 가정하에, 실제로 학습은 어떤 형태로 진행되는지 좀 더 Deep Learning 스러운 이야기들을 다뤄보도록 하겠다.
데이터 전처리(Kaldi) 스크립트에 대한 간략한 이야기 (TEMPLATE/asr1 참고)
정상적으로 스크립트가 돌아가면, Kaldi의 전처리 과정을 통해, 본인들이 원한 Feature에 대한 shape이나, 실제 실수 데이터값들이 npz등의 형태로 폴더에 생성되게 된다.
데이터의 전처리는 어디 depth 까지 사용하느냐에 따라, 처리 방법이 이 다양해서 명확하게 설명할 수는 없으나, 내가 주로 좀 유용하게 사용한 폴더와 파일들을 먼저 나열해보겠다.
TEMPLATE/asr1/asr.sh 발췌 (주석은 내가 달았음)
Stage 3. Kaldi를 이용한 데이터 전처리부
# 1. Copy datadir
utils/copy_data_dir.sh data/"${dset}" "${data_feats}${_suf}/${dset}"
# 2. Feature extract
# 여기서 fbank와 pitch를 뽑아내며, 두개의 특징을 합침.
_nj=$(min "${nj}" "$(<"${data_feats}${_suf}/${dset}/utt2spk" wc -l)")
# steps/make_fbank_pitch.sh --nj "${_nj}" --cmd "${train_cmd}" "${data_feats}${_suf}/${dset}"
# 필자는 참고로 make_fbank.sh쓴다. (아래와 같이 응용)
steps/make_fbank.sh --nj "${_nj}" --cmd "${train_cmd}" "${data_feats}${_suf}/${dset}"
utils/fix_data_dir.sh "${data_feats}${_suf}/${dset}"
# 3. scp파일별로 프레임 길이와 shape를 결정한다.
scripts/feats/feat_to_shape.sh --nj "${_nj}" --cmd "${train_cmd}" \
"${data_feats}${_suf}/${dset}/feats.scp" "${data_feats}${_suf}/${dset}/feats_shape"
# 4. 실제 feature로 사용될 디멘션 파일을 만든다.
head -n 1 "${data_feats}${_suf}/${dset}/feats_shape" | awk '{ print $2 }' \
| cut -d, -f2 > ${data_feats}${_suf}/${dset}/feats_dim
# 5. feats_type 뭐쓰는지 로그식으로 그냥 파일 남김.
echo "${feats_type}" > "${data_feats}${_suf}/${dset}/feats_type"
make_fbank.sh
make_fbank_pitch.sh
make_mfcc.sh 등등등~~~
- kaldi를 컴파일 설치 해야 쓸 수 있으며, 특징값을 뽑아서 파일로 만들어준다.
- 내부에서 사용하는 kaldi의 C base 소스는, compute-kaldi-fbank-feats, compute-kaldi-mfcc-feats 등등 각각 필요한 부분에서의 kaldi 소스가 사용되며, 해당 C 베이스 소스를 kaldi의 tools/steps 경로에서 찾아볼 수도 있고, 아니면 개발자 가이드도 있으니 참고하면서 차근차근 보면 이해하기 크게 어렵지는 않다. (http://www.kaldi-asr.org/doc/compute-fbank-feats_8cc.html)
- Kaldi에서 사용되는 음향 전처리에 대한 도메인 지식은 내가 Article을 따로 작성하여 곧 연결해놓도록 하겠다. (필자도 Fbank 같은 값들의 의미만 파악하고, 그것이 구체적으로 Kaldi에서 어떤 소스 부분에서 어떻게 동작하여 만들어지는지까지 보진 않았다. 도메인은 지식으로만 습득하고, Kaldi에서 개발자 가이드를 확인해보며 input, output을 판단해서 사용하는 역할정도로만 썼다.)
fix_data_dir.sh
- 이거 진짜 유용한데, 만약에 정렬같은걸 잘 안했거나, 파일에 문제가 있는 경우, 검증해주고, 문제가 무엇인지 지적해준다. 심지어 정렬같은거는 무시해도 자동으로 수행해주니 효자상품이다.
추가적으로 수행해줘야 하는 작업들이 있다면, 수행해준 뒤에,
Stage 10, 11로 학습을 선언하고, 실행하면 된다.
# Stage 10 일부 발췌
# shellcheck disable=SC2086
${train_cmd} JOB=1:"${_nj}" "${_logdir}"/stats.JOB.log \
${python} -m espnet2.bin.asr_train \
--collect_stats true \
--use_preprocessor true \
--bpemodel "${bpemodel}" \
--token_type "${token_type}" \
--token_list "${token_list}" \
--non_linguistic_symbols "${nlsyms_txt}" \
--cleaner "${cleaner}" \
--g2p "${g2p}" \
--train_data_path_and_name_and_type "${_asr_train_dir}/${_scp},speech,${_type}" \
--train_data_path_and_name_and_type "${_asr_train_dir}/text,text,text" \
--valid_data_path_and_name_and_type "${_asr_valid_dir}/${_scp},speech,${_type}" \
--valid_data_path_and_name_and_type "${_asr_valid_dir}/text,text,text" \
--train_shape_file "${_logdir}/train.JOB.scp" \
--valid_shape_file "${_logdir}/valid.JOB.scp" \
--output_dir "${_logdir}/stats.JOB" \
${_opts} ${asr_args} || { cat "${_logdir}"/stats.1.log; exit 1; }Stage 10에서는 train / valid set를 구분하고, espnet2 폴더 밑에있는 bin.asr_train 선언을 통해, 기본적인 클래스 선언과 내부에서 사용할 파라미터들이 정의되게 된다.
asr_train.py에는 ASRTask가 AbsTask를 상속하여 선언 되어있는데,
AbsTask class는 AbstractTask의 약자로 생각되며, Training에 구성될 최소 조건들과 또한 병렬처리를 지원하기위한 최소한의 껍데기와 같은 선언과 Action들이 선언되어 있다
그러면 ASRTask는 Training의 최소 조건이 되는 AbsTask를 가지고, 실제로 음향 처리 학습을 위한 어떤 동작을 수행할지에 대한 Action을 정의해놓게 된다.
=> AsrTask를 까보면, Layer에 대한 상세 구성과 Layer에 대한 파라미터 선택 등을 알 수 있다.
=> AbsTask를 까보면, 병렬처리, Data Input처리, model build, run training등에 대한 학습을 진행시키기 위한 내용등을 알 수 있다.
병렬처리에 대한 이해도가 낮거나, 상속에 대한 이해도가 낮으면 소스를 따라가는 것 자체가 어려울 수 있으나, 해당 아티클을 통해 차근차근 파악해나가보길 바란다.
# Stage 11 발췌
# shellcheck disable=SC2086
${python} -m espnet2.bin.launch \
--cmd "${cuda_cmd} --name ${jobname}" \
--log "${asr_exp}"/train.log \
--ngpu "${ngpu}" \
--num_nodes "${num_nodes}" \
--init_file_prefix "${asr_exp}"/.dist_init_ \
--multiprocessing_distributed true -- \
${python} -m espnet2.bin.asr_train \
--use_preprocessor true \
--bpemodel "${bpemodel}" \
--token_type "${token_type}" \
--token_list "${token_list}" \
--non_linguistic_symbols "${nlsyms_txt}" \
--cleaner "${cleaner}" \
--g2p "${g2p}" \
--valid_data_path_and_name_and_type "${_asr_valid_dir}/${_scp},speech,${_type}" \
--valid_data_path_and_name_and_type "${_asr_valid_dir}/text,text,text" \
--valid_shape_file "${asr_stats_dir}/valid/speech_shape" \
--valid_shape_file "${asr_stats_dir}/valid/text_shape.${token_type}" \
--resume true \
--fold_length "${_fold_length}" \
--fold_length "${asr_text_fold_length}" \
--output_dir "${asr_exp}" \
${_opts} ${asr_args}Stage 11에서는 실제로 Training을 Run 하게 되며,
launch.py는 GPU나 slurm pool 혹은 멀티 node (다중 클러스터 같은) 환경에서의 구성을 하고 subprocess를 이용하여 각각의 병렬 처리로 asr_train을 진행하게 된다. 개발자 가이드를 확인해보면 각 파라미터의 설명을 확인해볼 수 있는데, 특히나 --resume을 이용하게 되면, 모델이 있는경우 이어서 학습하게 되므로, 유용하게 쓸 수 있다. 참고하도록 하자.
결과적으로는 직접 쉘 스크립트에서 선언하여 집어넣거나, conf 폴더에서 선언한 파라미터들을 가지고,
AsrTask에서는 모델에서 쓰일 값들의 선택을,
launch와 AbsTask에서는 어떻게 Training Process를 진행시킬지에 대한 선택들을 하며,
학습이 진행되게 된다.
뭐 그 이후에는, 검증(Stage 12)을 하거나 해서 Scoring(Stage 13)을 뽑아보면 학습이 완벽하게 끝나게 된다.
Training Process야, 검증된 Open Source Reference이니, 기울기 최적화 되게 잘 Torch로 짜져있다고 생각하고, 우리는 Layer의 구성이나, 처리의 흐름, Attention의 사용, 선택할 수 있는 값들은 무엇들이 있는지 상세하게 살펴보도록 하자.
abs_task.py
여기서는 어떤 흐름을 다룬다기 보다는 이슈를 위해서 잠시 들렸다. 가장 시작부분이기도 하고.
일단 main()을 참고하면, 어떻게 진행되는지 따라가볼 수 있다.
내가 ESPNet을 파이썬 가상환경과 Docker환경으로 전부 구성해봤는데, 참고해야될 부분은, 개발환경으로 Docker로 구성하게되면, 일단 Docker Container를 본인의 Local이나 혹은 DEV Server에서 세팅을 하게 될텐데, 그러면 Host-Guest가 동일한 Node가 되면서, SSH 접속을 통한 Multi Node Sub Process 생성이 유연하게 되지않아, 학습이 진행되지 않는 불편함을 겪을 수 있다.
해당 이슈는 abs_task.py의 multiprocessing_distributed flag가 관장하고 있으며, 해당 Flag를 false로 해줘야 Host=Guest 환경이나 다름없는, 1대짜리 node에서 Container를 구성했을때 정상 동작한다.
소스를 따라가다보면, build_model을 확인할 수 있는데, 해당 abstractmethod는 asr.py의 ASRTask에 선언되어 있으며, 여기서 실제 모델의 구조를 확인해볼 수 있다.
asr.py
딥러닝을 다뤄봤다면 이제야 좀 익숙한 소스들이 나오기 시작한다.
class choice 부분이 있어서, 위로 올라갔다 내려갔다하면서, 선택 가능한 값들이 무엇들이 있는지 파악을 해야하는 수고로움은 있지만, 차근차근 따라가다보면 어떻게 구성되어있는지 다 알 수 있긴 하다.
Data Set & Pre-Processing
# asr.py 발췌
# 1. frontend
if args.input_size is None:
# Extract features in the model
frontend_class = frontend_choices.get_class(args.frontend)
frontend = frontend_class(**args.frontend_conf)
input_size = frontend.output_size()
else:
# Give features from data-loader
args.frontend = None
args.frontend_conf = {}
frontend = None
input_size = args.input_size
# 2. Data augmentation for spectrogram
if args.specaug is not None:
specaug_class = specaug_choices.get_class(args.specaug)
specaug = specaug_class(**args.specaug_conf)
else:
specaug = None
# 3. Normalization layer
if args.normalize is not None:
normalize_class = normalize_choices.get_class(args.normalize)
normalize = normalize_class(**args.normalize_conf)
else:
normalize = None

Data Set & Pre-Processing
데이터 준비 및 전처리다. 해당 step에서 frontend가 있기 때문에, 아마 Kaldi를 선택적으로 사용해도 된다고 하는 것일 거라고 판단된다. (필자야 Kaldi 썼으니 frontend 돌리면 안된다.)
frontend는 소스에도 주석으로 있긴한데, Stft -> WPE -> MVDR-Beamformer -> Power-spec -> Mel-Fbank -> CMVN 과정을 진행해주는 것이다. 음향 전처리에 대한 내용인데, 자세한건 음향처리 도메인을 설명하는 아티클을 따로 작성하겠다. (specaug도 마찬가지)
화자 데이터 정규화는 소스를 보면 그냥 들어온 값에 대한 Mean Variance 정규화로, Standard Scaler와 비슷한 역할을 할 것으로 보인다. (음향 데이터도 실수 범위 값이기 때문에, 정규화를 하는 것이 좋다.)
Encoder 선언부
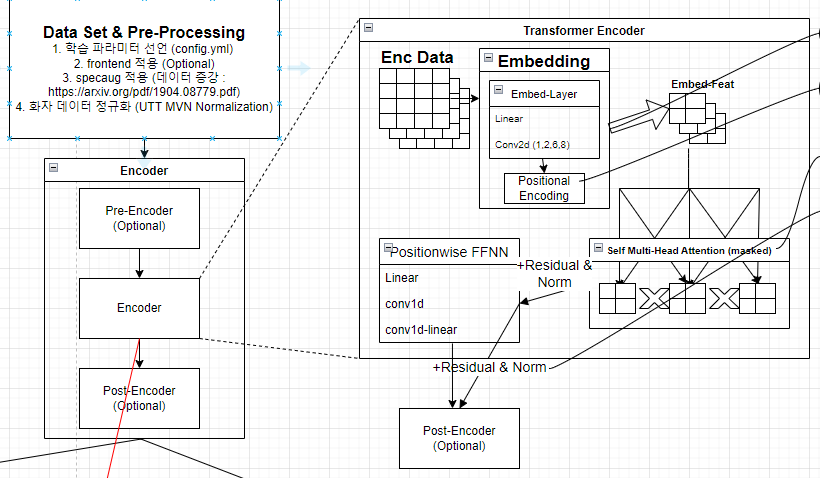
# 4. Pre-encoder input block
# NOTE(kan-bayashi): Use getattr to keep the compatibility
if getattr(args, "preencoder", None) is not None:
preencoder_class = preencoder_choices.get_class(args.preencoder)
preencoder = preencoder_class(**args.preencoder_conf)
input_size = preencoder.output_size()
else:
preencoder = None
# 4. Encoder
encoder_class = encoder_choices.get_class(args.encoder)
encoder = encoder_class(input_size=input_size, **args.encoder_conf)
# 5. Post-encoder block
# NOTE(kan-bayashi): Use getattr to keep the compatibility
encoder_output_size = encoder.output_size()
if getattr(args, "postencoder", None) is not None:
postencoder_class = postencoder_choices.get_class(args.postencoder)
postencoder = postencoder_class(
input_size=encoder_output_size, **args.postencoder_conf
)
encoder_output_size = postencoder.output_size()
else:
postencoder = NonePre-Encoder
1) LightweightSincConvs
- convolution layers를 사용한 인코더
- https://arxiv.org/abs/2010.07597
Lightweight End-to-End Speech Recognition from Raw Audio Data Using Sinc-Convolutions
Many end-to-end Automatic Speech Recognition (ASR) systems still rely on pre-processed frequency-domain features that are handcrafted to emulate the human hearing. Our work is motivated by recent advances in integrated learnable feature extraction. For thi
arxiv.org
2) LinearProjection
- dnn을 이용한 인코더
를 선택할 수 있다.
의도 자체는 그냥 raw 데이터를 layer를 통과하게 해서 학습가능하게 하고, Attention을 진행시키거나 함에 있어서 좀 더 Feature Extraction이 잘되게 하기 위함일거라고 판단된다.
Encoder
1) Conformer Encoder
- conv2d+dnn+Attention 형태의 인코더
- 뭔가 OCR처럼 학습이 될까? 싶다
2) Transformer Encoder
- Attention으로만 조지는 인코더
- embed -> Self와 일반 Attention, Norm으로 이루어지는 평이한 Attention Based Encoder이다.
- Masked를 이용하여, pad를 처리해놨다 (추후에 Transformer만 따로 Article을 작성할까보다.)
3) ContextualBlock Transformer Encoder
- https://arxiv.org/abs/1910.07204
Transformer ASR with Contextual Block Processing
The Transformer self-attention network has recently shown promising performance as an alternative to recurrent neural networks (RNNs) in end-to-end (E2E) automatic speech recognition (ASR) systems. However, the Transformer has a drawback in that the entire
arxiv.org
- 이것도 뭔가 Conformer랑 비슷해보이는데, 얘가 좀 더 OCR처럼 동작하긴한다, Block을 정해서 뭔가 sliding 하듯이 진행되는 것 처럼 보인다.
4) VGGRNN Encoder
- 그냥 VGG+RNN(lstm or gru). BI 지원
5) RNN Encoder
- 무지성 RNN(lstm or gru). BI 지원
6) FairSeqWav2Vec2Encoder
- vgg할때 쓰이는 pre-trained 모델처럼, wav2vec2라는 pre-trained 모델이 있는 것 같고, 거기서 학습된 파라미터만 뽑아서 진행하게 되는 형태의 Encoder로 보인다.
Post-Encoder
1) HuggingFaceTransformersPostEncoder
- HuggingFace에서 제공하는 인코더로 pre_trained 모델을 사용하는 것 같으며, Embed - Attention의 형태인 것 같다.
휴, 이제 인코더 다 끝났다.
Decoder 선언 부 + 실제 Model Build(파라미터 초기화)
# 5. Decoder
decoder_class = decoder_choices.get_class(args.decoder)
decoder = decoder_class(
vocab_size=vocab_size,
encoder_output_size=encoder_output_size,
**args.decoder_conf,
)
# 6. CTC
ctc = CTC(
odim=vocab_size, encoder_output_sizse=encoder_output_size, **args.ctc_conf
)
# 7. RNN-T Decoder (Not implemented)
rnnt_decoder = None
# 8. Build model
model = ESPnetASRModel(
vocab_size=vocab_size,
frontend=frontend,
specaug=specaug,
normalize=normalize,
preencoder=preencoder,
encoder=encoder,
postencoder=postencoder,
decoder=decoder,
ctc=ctc,
rnnt_decoder=rnnt_decoder,
token_list=token_list,
**args.model_conf,
)
# FIXME(kamo): Should be done in model?
# 9. Initialize
# deep learning param init이니까 자세한 설명은 생략한다.
if args.init is not None:
initialize(model, args.init)
Decoder
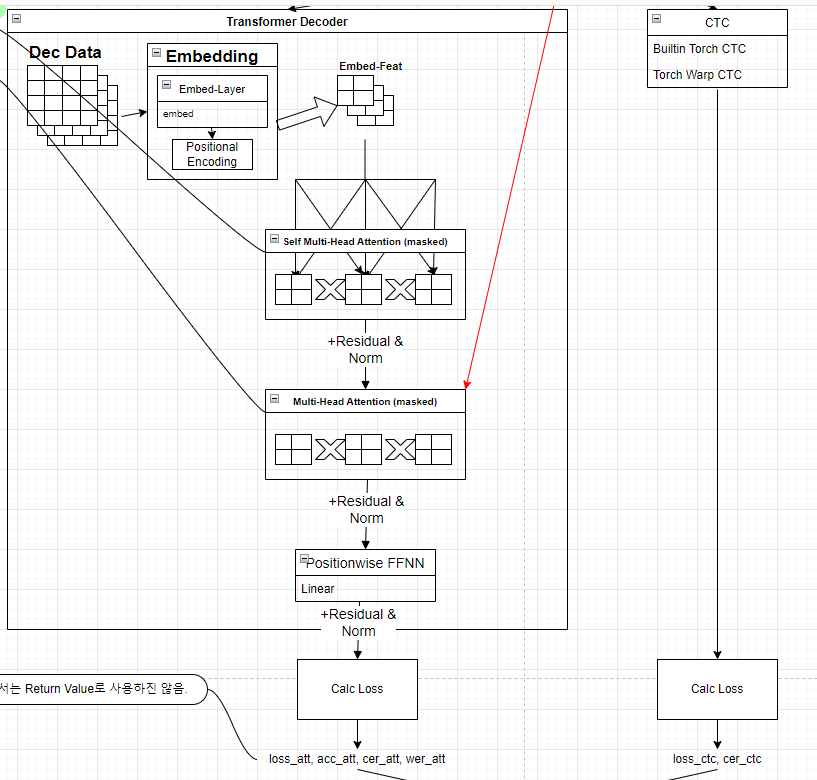
특징으로는, Encoder와 관계 때문인지, 일단 Attention은 무조건 사용하려는 모습이고, 다만 Text Vector의 학습을 어떻게 Layer로 학습을 구성하느냐로 고민한 것 같다.
1) Transformer Decoder
- Transformer Encoder와 항상 묶여다니는 Transformer 형제랑 똑같다.
- embed -> Self와 일반 Attention, Norm으로 이루어지는 평이한 Attention Based Decoder이다.
- Masked를 이용하여, 교사강요를 처리해놨다.
2) LightweightConvolutionTransformerDecoder
- linear -> glu > lightconv -> linear -> attention을 사용한다.
- https://github.com/pytorch/fairseq/tree/master/fairseq
GitHub - pytorch/fairseq: Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
Facebook AI Research Sequence-to-Sequence Toolkit written in Python. - GitHub - pytorch/fairseq: Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
github.com
3) LightweightConvolution2DTransformerDecoder
- 1D conv가 있다면 거의 항상 무지성으로 있는 2D
4) DynamicConvolutionTransformerDecoder
- linear -> glu -> (병합) -> lightconv -> linear -> attention
-> linear ->
5) DynamicConvolution2DTransformerDecoder
- 1D conv가 있다면 거의 항상 무지성으로 있는 2D
6) RNNDecoder
- 무지성 RNN(lstm or gru). BI 지원
CTC
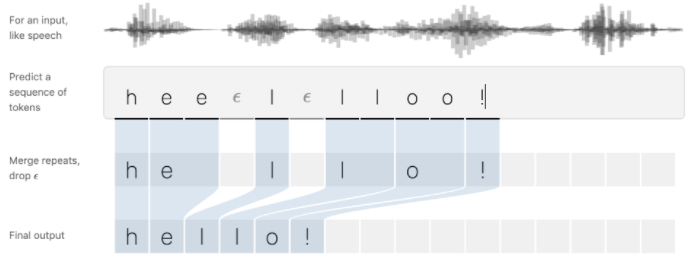
- CTC란, 단어 시퀸스 - 음소 시퀸스 간의 명시적인 얼라인먼트가 없어도 음성인식 학습을 가능하도록 설계된 알고리즘이다.
- 연속된 음소를 분석할 때 제거할지, 말아야할지 애매했는데 CTC는 이를 블랭크(-) 를 활용해서 이를 제거할 수 있도록 하였다.
- CTC를 이용해 모든 가능한 순서에서 분류 확률을 최대화 할 수 있는 모델을 학습한다.
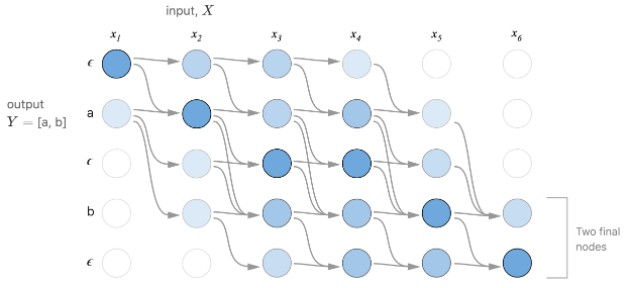
- 전방확률로써, a일때 b가 나올수 있는 모든 확률을 구해야한다.
- CTC는 조건부 독립을 가정한 상황이므로 해당 시점에 확률을 단순히 모두 덧셈을 해주면 된다.
- 하지만 이러한 경우 음소가 길어지게 된다면, 계산량이 폭증하게 되는 단점이 있다. (속도가 매우 느려짐)
- 조건부 확률을 이용하여 전방, 후방확률을 계산 및 최대우도를 찾아나가는 과정으로, HMM과 원리가 비슷하며, DNN과도 형태가 사뭇 비슷하다.
- 여기서는 BeamSearch를 이용하여 찾아낸 최대 가능성의 값과 실제값의 차이를 loss로 활용한다.
- Torch에서 제공하는 CTC 알고리즘을 사용한다. (Builtin Torch CTC, Torch Warp CTC 중 택1)
Build Model
- ESPnetASRModel 클래스를 보면 실제로 어떻 Flow로 진행되는지 확인할 수 있다.
espnet_model.py (ESPnetASRModel Foward Flow)
# 1. Encoder
encoder_out, encoder_out_lens = self.encode(speech, speech_lengths)
# 2a. Attention-decoder branch
if self.ctc_weight == 1.0:
loss_att, acc_att, cer_att, wer_att = None, None, None, None
else:
loss_att, acc_att, cer_att, wer_att = self._calc_att_loss(
encoder_out, encoder_out_lens, text, text_lengths
)
# 2b. CTC branch
if self.ctc_weight == 0.0:
loss_ctc, cer_ctc = None, None
else:
loss_ctc, cer_ctc = self._calc_ctc_loss(
encoder_out, encoder_out_lens, text, text_lengths
)
# 2c. RNN-T branch
if self.rnnt_decoder is not None:
_ = self._calc_rnnt_loss(encoder_out, encoder_out_lens, text, text_lengths)
if self.ctc_weight == 0.0:
loss = loss_att
elif self.ctc_weight == 1.0:
loss = loss_ctc
else:
loss = self.ctc_weight * loss_ctc + (1 - self.ctc_weight) * loss_att
stats = dict(
loss=loss.detach(),
loss_att=loss_att.detach() if loss_att is not None else None,
loss_ctc=loss_ctc.detach() if loss_ctc is not None else None,
acc=acc_att,
cer=cer_att,
wer=wer_att,
cer_ctc=cer_ctc,
)
# force_gatherable: to-device and to-tensor if scalar for DataParallel
loss, stats, weight = force_gatherable((loss, stats, batch_size), loss.device)
return loss, stats, weight모델 빌드는 위에서 확인했으니 여기서는 순서만 확인해도 될 것이다.
1. Encoder를 진행
2. Attention Decoder/CTC를 병행으로 진행한다.
3. Loss 계산
- CTC와 ATT의 비율로 계산한다. (논문에도 나와있었지...ㅋㅋ)
이렇게 하면 알아서 ABSTask에서 Optimizing 해가며 학습이 잘 진행될 것이다.
(사실 Loss 이후에 BackPropa 부분까지는 소스리뷰 하진 않았다... 거기까지 뭔가 Logging해야되거나 하면 볼 생각이다...ㅋㅋㅋ)
Model Training 총평
여기까지 하면, Training은 전부 소스를 까봤다고 할 수 있겠다.
어떤가? 논문이랑은 말이 잘 맞는것 같은가?
2021.05.14 - [논문으로 현업 씹어먹기] - 딥러닝 STT 모델 - ESPNet (1)
딥러닝 STT 모델 - ESPNet (1)
BERT부터 설명을 하려고 하긴 했는데, 이제 곧 업무가 시작되기도 할 것이며, 최근에 논문을 읽어본 ESPNet에 대해서 먼저 정리해보겠다. 서론 사실 이전 회사에서, 크롤링 -> Text Analysis(TA) -> Power BI
shyu0522.tistory.com
일단 소스 리뷰를 하면서 최초보다 더 알게 된 점은, 일단 행렬곱때문에 문장 길이나 음성 길이가 길어지면, 속도가 느릴 것은 분명하다.
음성 길이가 길어지면, 적중율이 떨어질까?
Attention을 보면 Score에서 정규화 부분이 있어서, 적중율 떨어질 것 같진 않은데.... 얼마 길이까지 수용 가능할지 궁금하긴하다.
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)뭐 sqrt한다고 해도, 겁나게 길어지면 한계가 있긴 있겠지....
제공 기능은 엄청 많은 것 같긴하다. 또한 소스만 조금 수정하면, 내가 해보고 싶은 Torch 알고리즘을 추가하여, Encoder Decoder를 쉽게 구성해볼 수도 있을 것 같다. (R&D의 영역이 되겠지)
그리고 CTC와 Attention의 Weight를 극단적으로 조절하여 테스트도 진행해봤는데,
CTC-Weight 값이 커질수록 발성, 소리에 맞춰진다. (들었을때 갔어여면 갔어여로 찍힘)
Attention-Weight 가 커질수록 문법적인 것에 맞춰, 실제 발음에 대한 의존성 정보를 간접적으로 표현한다. (갔어여라고 들려도 갔어요라고 찍힘)
그리고 CTC를 사용해서 자모분리 학습을 하게 되면, 자모로 학습하는 것은 불필요한 연산이 늘어날 것 같고, Beam-Search를 통한 자모의 선택이 학습이 조금 안되더라도, 전혀 한글로 예상조차 되지 않는 단어로 예측될 것 같기도 하다.
(데이터가 진짜 많고, 발화가 짧은 문장이라던가, 언어모델이 있는 경우에만 권장할 수 있을 것 같다는 판단이 선다.)
R&D나 특정 고객 향으로 엔진을 고도화 할 것이 아닌, 단순 SI 사상으로 Integration만 고려한다면, 사실 해당 소스들은 모르고 그냥 설정만 잘 해서 사용해도, 어느정도 모델이 나오고 학습이 잘 진행될 것으로 판단되긴한다.
(대신, 그렇게 사용하면 이것저것 실험은 못해보겠지)
어느정도 이제 ESPNet이라는 모델이 어떻게 구성되어있고, 학습에 있어 어떤 선택지가 있으며, 어떤 Flow로 진행되는지 알아보았다.
다음시간에는 일단 음성처리 도메인을 한번 정리할까 싶다.(푸리에 변환같은...)
그 이후에 Inference Flow를 한번 볼까 한다.
양많아서 막막했는데 어찌저찌 하니까 되긴 되네....ㅋㅋㅋ
'딥러닝으로 하루하루 씹어먹기' 카테고리의 다른 글
| 딥러닝 STT 모델 - ESPNet (6 - Inference, Predict 시작!) (3) | 2021.11.15 |
|---|---|
| 딥러닝 STT 모델 - ESPNet (5 - 음성처리 도메인) (0) | 2021.10.25 |
| 딥러닝 STT 모델 - ESPNet (3 - 환경구성만 1 Article) (0) | 2021.10.21 |
| 딥러닝 STT 모델 - ESPNet (2 - 톺아보기) (2) | 2021.05.24 |
| 딥러닝 STT 모델 - ESPNet (1) (5) | 2021.05.14 |

댓글