모델을 이것저것 경험해보는 것을 무척이나 좋아하는 편이라, 회사에서 중간 의사결정권자로써 많은 모델들을 개발해보려고 노력하고있다.
와중에 OCR Task가 생겨서 진행해봤던 논문인 TrOCR을 한번 리뷰해보고자 한다.
VALL-E는 구현체도 없고 내용도 조금은 어려울 수 있어서 거의 직역에 가까운 리뷰를 진행했는데, 이번 TrOCR은 HuggingFace에서 간단하게 사용해볼 수 있고, 논문 리뷰 전에 한번 사용해보니 Pre-Trained Image Transformer Encoder + Pre-Trained Transformer De(En)coder Causal(Masked)LM 의 구조를 띄고 있는거라, 논문에 앞서 한번 상상해보면, 1) Image Transformer를 손글씨로 학습함. 2) Text Transformer는 그냥 PLM 사용함 -> 그랬더니 매우 잘되더라. 하는 내용이지 않을까 싶어서, 약간은 요약 형태로 작성해보고자 한다.
Abstract
기존에는 CNN으로 이미지를 이해하고 RNN으로 Text를 예측하고, 필요하면 추가적인 Language Model을 응용하는 형태로 OCR을 해오고 있었다. 하지만 이번 논문으로 Transformer En-Decoder 모델로 Pre-Trained까지 가능한 OCR Task가 가능해질 것이다.
Introduction
OCR은 타이핑되던, 손으로 썼던, 출력됐던 이런 지로 자료를 스캔, 이미지 등으로 변환하여 Digitalize하는 것이다. 일반적으로 OCR은 2가지 모듈로 되어있는데 text detection Module과 text recognition Module이 있다. text detection은 텍스트 이미지에서 글자단위던, 문장단위던 문자의 위치를 파악하는 것이다. text detection 작업은 일반적으로 YoLOv5와 DBNet과 같은 모델을 적용해볼 수 있다. text recognition 작업은 visual 신호에서 natural language tokens를 전사하는 것이다. encoder-decoder 형태의 CNN(이미지)-RNN(텍스트)으로 처리하는게 일반적이었다. 이 논문에서, text recognition 작업에 초점을 맞췄으며, text detection 작업은 future work로 남겨뒀다.
최근에도 text recognition은 transformer를 도입하면서 많이 개선이 됐었다. 그래도 뭐 여전히 백본은 CNN based였고 CNN 위에 self-attention 를 적용하는 식이었고, 디코더를 CTC를 사용하는 방식이었다. character-level로 해서 성과를 많이 보였다. hybrid en/decoder 형태들도 있었는데, 1) Computer Vision(CV)와 NLP를 pre-trained하는 것으로 더 많은 개선의 여지들을 남겨두고 있었다. 2) Image Transformers가 유명해지는 것으로 image pre-training이 가능해졌는데, 이것이 CNN 백본을 대체할 수 있음을 조사해볼 수 있겠으며, Pre-Trained된 Image Transformers와 NLP Transformers를 가지고 text recognition task를 해결해보면 그만이다.
마지막으로, TrOCR을 소개한다. end-to-end Transformer-based OCR model이며, Pre-Trained돈 CV와 NLP Model이다. TrOCR은 CNN을 사용하지 않고도 간단하고 효과적으로 적용해볼 수 있다. 첫번째로 input image를 384X384로 resizes하고 16X16 Patches로 쪼갠다. (이 부분은 ViT 지식이 있어야 이해 가능할듯)
ViT: Vision Transformer의 약자로, Image를 16X16으로 쪼개서 일일이 Pixels 단위로 계산할 필요를 줄인다. 16X16으로 쪼개는걸 Patches라고 표현하며 CNN Layer의 Stride와 Kernel을 동일하게 16으로 맞춰서 처리한다. CNN Layer를 크게 해석해서 임베딩이라고 하고 Pixels단위 이미지를 16X16단위 크기로 임베딩하여, Self-Attention하는 것으로 Transformer Encoder 학습을 진행한다. Pre-Training은 (self-supervised) Masked 맞추는 방법이 있고, (supervised) Image Classification하는 방식이 있는데, supervised가 더 잘됐다고 한다. 장점은 CNN 에서 하는 것과 비슷하게 Transformer로 선행학습하여 이미지를 잘 해석할 수 있는 모델을 만들 수 있었다는점이나, 단점으로는 CNN을 완벽하게 구현해내지 못했으며 (Window Sliding이 없으므로, Stride, Pooling효과 같은게 약함), 이 역시도 이미지가 겁나 커지면 Patches를 늘려야 잘되는데, Patches를 늘리면, self-attention에서 속도가 겁나 느려짐.
=> 이 두 문제를 정확하게 해결하기위해 Microsoft에서 swin transformer를 발표하는데, 이것은 window를 통해서 stride, pooling 효과를 전부 가지며, window내의 patches끼리만 Attention하므로, 기존에 이미지 크기에 제곱되서 증가하던 patches의 계산량이 window 내의 patches로 국한되므로 매우 작아진다.
해당 patches로 쪼개진 image input을 transformer encoder를 통해 decoder로 전달되며, text decoder가 인식된 text를 생성해내는 형태로 구현되었다. 논문에서는 TrOCR은 Encoder는 pre-trained VIT-style models로 초기화 되며, Decoder는 pre-trained된 BERT-style models로 초기화 된다고 한다. 그러므로 TrOCR의 장점은 3개가 있다고 한다.
1. TrOCR은 추가적인 language model을 필요로 하지 않으며, 잘 사전학습된 Pre-trained Image Models(PIM), Pre-trained Language Models(PLM)을 사용하면 된다.
2. CNN을 백본으로 가져갈 이유가 없으며, 개발이 용이하고 유지보수가 쉽다.
3. 추가적인 전, 후처리 필요없이 SOTA달성.
최종적으로, 최소한의 노력으로 decoder 부분 dictionary 확장을 통한 multilingual 할 수 있을 것으로 보임.
TrOCR
Model Architecture

PIM이 patches 단위의 visual feature 추출, PLM이 wordpiece 단위의 langauge modeling수행. vanilla Transformer En-Decoder 구조를 사용함. (물론 이거는 PIM, PLM이면 patches가 아닌 window 단위가 될 수도 있고, wordpiece가 아니라 char단위가 될 수 도 있다. 모델을 뭐 쓰냐에 따라 얼마든지 응용 가능하다는 점을 꼭 기억하자)
Encoder
ViT를 알고있다면 읽어볼 필요 없다. 동일한 내용임.
기존에 RGBxHxW 던게 아니고 RGBxPxP가 된다. 때문에 input image는 HW/P^2가 된다. 이녀석들은 flattened되어서 linearly projected to D-dimensional vector가 된다. (정확히는 ViT논문 읽어보면 알지만 2D-CNN써서 처리한다.) 이거를 Patch Embedding이라고 표현한다. ViT와 DeiT와 유사하게, [CLS]토큰을 유지하고, 이것은 뭐 PLM 해봤으면 알 수 있듯이 모든 정보를 담고있다고 표현하면 된다. DeiT pre-trained모델의 encoder initialize를 위해서 distillation token을 유지해야한다. teacher model로부터 모델을 학습할 수 있기 위함이라고 한다. (DeiT는 정확히 모르겠어서 distill learning하기 위한 뭔가 세팅을 유지해야 하는듯)
CNN방법론과는 다르게 inductive biases가 없고, patches 순서에 집중하므로, 각각에 pathces 독립에 따라 attention이 집중될 여지가 있다. (이거 역시 swinv2에서 해결된다)
Inductive Biases: 모델이 본 것만 잘 맞추게 할 것인가, 안본 것도 어느정도 귀납적 추론이 가능하게 할 것인가? Inductive Biases는 후자에 집중한다. 일부를 보더라도, 전체를 알 수 있게 하는 CNN의 방식은 "이런 귀 모양이면 강아지일껄?" 과 같은 Inductive Biases를 가질 수 있다. 근데 Fully Connected같은 경우는, 부분을 본다는 것 자체가 아이러니한 명제이므로 (Fully Connectied는 부분을 볼게 없이, 무조건 전체를 본다고 가정하니까.) 강아지 그림에서 귀모양만 보내줘서는 잘 안맞을 가능성이 있다. (운좋게 맞출 수도 있지만.) 그래서 FFN같은 경우는 Inductive Biases가 약하다고 한다. (내가 왜 FFN을 여기서 비교하는지는 알겠죠? Transformer도 잘 생각해보세요...)
Decoder
Transformer En-Decoder형태의 Transformer Decoder에 대한 설명이 나온다. Transformer Deocder구조 그대로를 떠들고 있으니 (교사강요 설명까지 해줌...ㅋㅋ) 잘 기억이 안난다면 잘 설명되어있는 한글 구글러들 내용을 보고오자.
Model Initialization
공개된 Pre-Trained Model을 불러와 사용함.
Encoder Initialization
DeiT, BeiT 를 사용해봄. 둘에 대한 간략한 설명이 나온다.
DeiT: Distill Learning을 사용함. 저자가 하이퍼파라미터를 이것저것 바꿔보고 augmentation을 이것저것 모델에 적용해봤음.
BeiT: Masked Language Model Task처럼 학습된 모델. 이미지를 Discrete VAE를 통해 원복시켜서 masked를 학습시키나보다. DeiT랑 다르게 distilled token이 없음.
Decoder Initialization
RoBERTa와 MiniLM을 사용해봄.
RoBERTa: 하이퍼 파라미터와 데이터 사이즈 변화로 영향을 면밀히 조사함. Masked를 학습간 random하게 적용하고, NSP loss가 없음.
MiniLM: 99%의 퍼포먼스를 유지하지만, large model을 압축한 형태. distillation하게 학습되었음.
이런 모델 load하다보면 어떤 파라미터는 Transformer decoder에 있고 없고 할텐데, 없는건 랜덤초기화 했음.
Task Pipeline
글씨 이미지를 주고 텍스트를 생성하는 문제. [BOS], [EOS]토큰을 text에 사용하였음. cross-entropy loss 사용. [BOS]로부터 Decoder는 예측 시작.
Pre-training
pre-training과정에서 text recognition task를 적용해서 진행함. Visual feature extraction 그에 대한, language modeling을 학습할 수 있기를 기대함. pre-training은 2 stage로 나누어서 진행함. 첫번째 stage에서, printed textline images를 수억개 만들어서, TrOCR을 학습시킴. 두번째 stage에서, 2개의 상대적으로 적은 datasets를 활용함. printed or handwritten downstream task로 활용. public dataset으로 수백만개 사용함. 두번째 stage에서 load된 첫번째 stage의 모델 parameter도 미세조정 될 것임.
Fine-tuning
text recognition task에서 미세조정되며, model의 출력물은 BPE와 SentencePiece에 영향을 받으며, 작업관련 vocab에 의존하지 않습니다. (마지막 문장은 무슨뜻인지 모르겠다?)
Data Augmentation
원본+6개의 변형이미지 활용하였음. (printed, handwritten 각각)
random rotation (-10 to 10 degrees), Gaussian blurring, image dilation, image erosion, downscaling, underlining. 각 샘플에 대해 동일한 가능성으로 어떤 이미지 변환을 수행할지 무작위로 결정함. scene text datasts의 경우, (Atienza 2021)를 따르는, RandAugment을 적용했으며, inversion, curving, blur, noise, distortion, rotation, etc를 포함한다.
Experiments
Data
Pre-training Dataset
684M textlines 이미지를 PDF에서 구해서 짤라가지고 stage1에 활용. 5427개의 폰트에 대한 손글씨를 TRDG라는것으로 만들어냄. TextRecognitionDataGenerator 오픈소스 툴임. Wikipedia 랜덤 페이지 클롤링함. second-stage pre-training에서 17.9M textlines 사용. IIIT-HWS 데이터셋도 추가해서 함. 추가적으로 53K의 상용 OCR엔진을 이용해서 만들어냄. TRDG써서 1M개의 2개의 폰트를 가지는, printed textline image 데이터셋도 만듬. 총합적으로 printed는 3.3M. scene text recognition을 위해서는 MJSynth와 SynthText데이터 16M text images 사용.
대충 이정도 만큼이 필요하다는 것 정도만 알면 되지 않을까 싶다.
Benchmarks
SROIE dataset (scan text)으로 test. text detection은 예정에 없었으므로, 다 crop해서 사용했음.
IAM Handwriting Database도 사용함.
scene text images는 이미지가 상한게 많아서 좀 더 어렵다. IIIT5K-3000, SVT-647, IC13, IC15, SVTP, CT80 등의 검증용 데이터로 활용함.
Settings
Fairseq으로 개발했고, DeiT는 timm library에 있는 것을 활용, BeiT, MiniLM, UniLM은 오피셜 레포에 있는 모델 활용. RoBERTa는 Fairseq GitHub Repo에 있는 것 활용. 32Gb V100x32를 pre-training에, 8개를 Fine-Tuning에 활용. batch size 는 2048, lr 5e-5, BPE, sentencepiece tokenizer는 fairseq 활용.

Baseline으로는 CRNN활용. CTC loss로 학습된 모델임. PyTorch Implement 활용 및 pre-trained parameter 초기화 함.
Evaluation Metrics
IAM은 CER로 처리

Scene text는 WER로 처리
lowcase 알파벳 36개만 사용.
Results
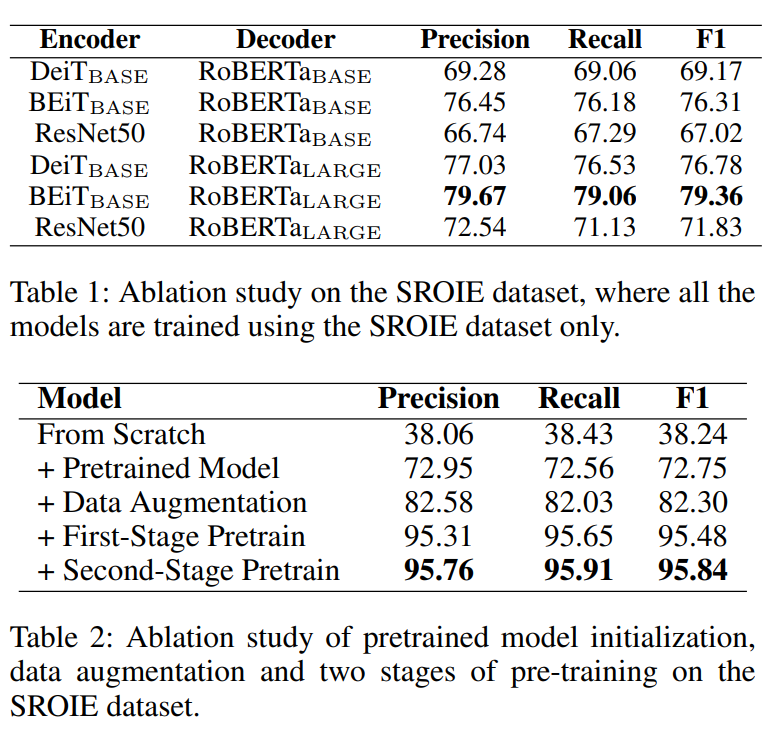
Table 1은 모델 구조별 잘되는 것을 찾아본 것이다. (Image Encoder의 영향을 많이 받는 것 같고, Decoder는 클 수록 좋음)
Table 2는 어디까지 pretrain된게 제일 잘될까?이다. (뭐 당연 많이한게 잘됨)
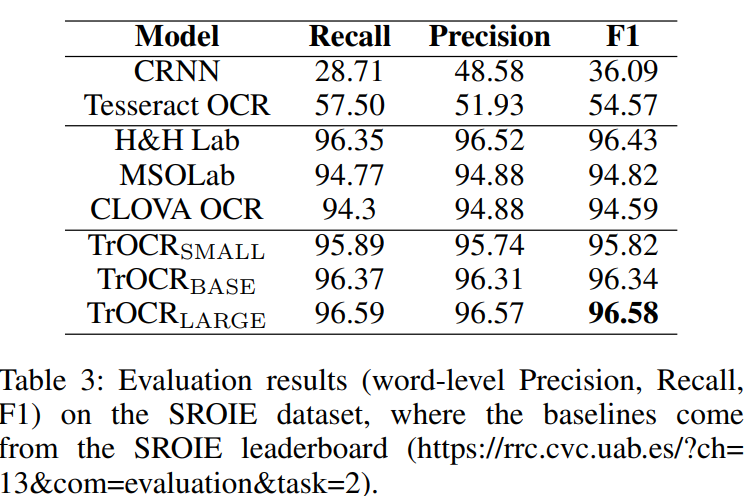
Table 3은 SROIE로 나름 SOTA라는 놈들과 비교한 것이다.
이거는 비교군이 전부 CNN or RNN or RCNN Based로 LSTM, GRU정도의 차이만 가지고 있어서, 당연 TrOCR만큼 못따라올만 하다. (그나저나 2022년 하반기 논문인데 클로바가 아직도 LSTM based인가보다?)
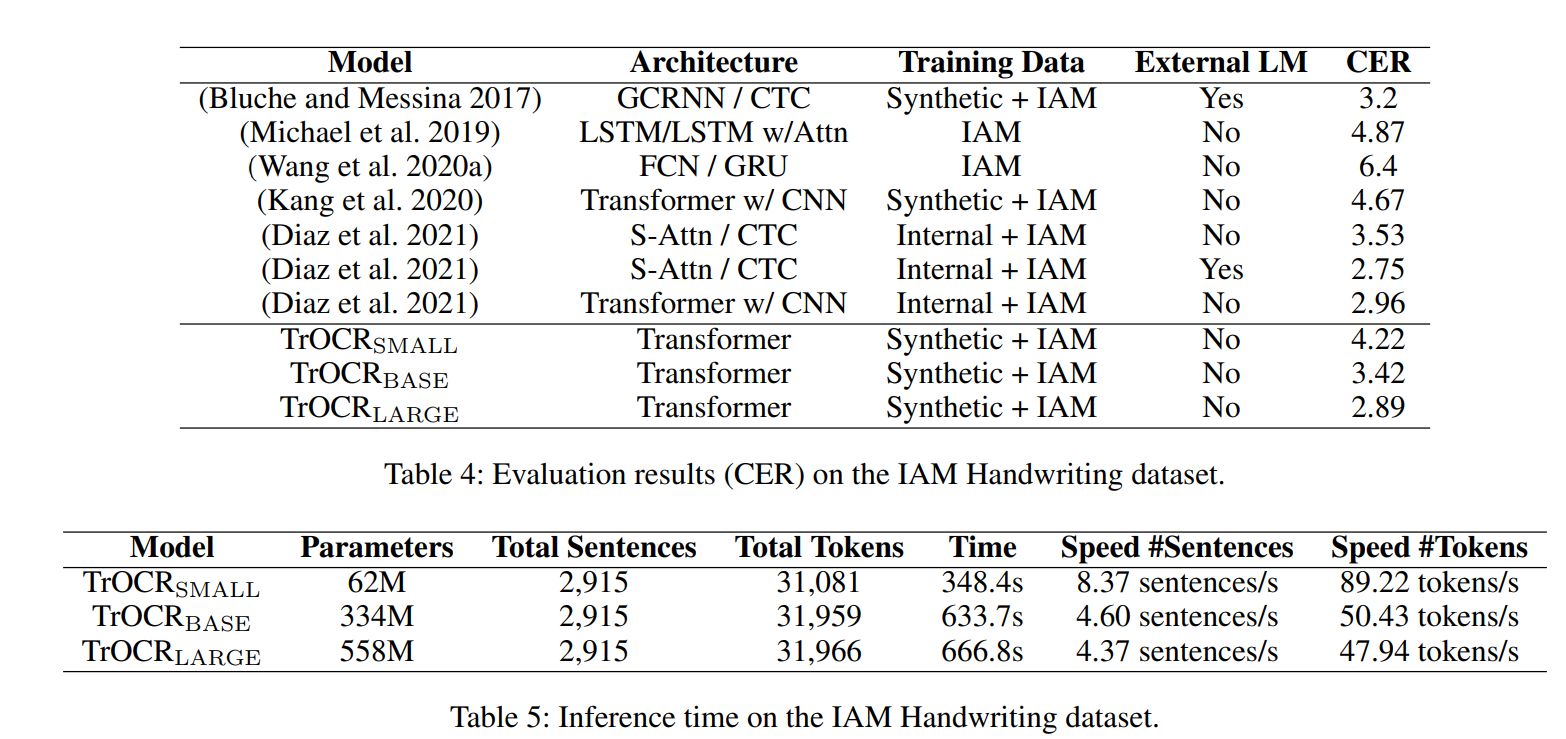
Table 4는 IAM에 대한 결과로, Transformer 기반의 CTC로 학습된 모델이더라도 LM을 사용하면 꽤나 잘나오는 것을 알 수 있다. 그래도 TrOCR Large에는 못미치며, CTC decoder보다 Transformer decoder generate 성능이 더 좋아서 그럴 것이라고 한다. LM을 쓰지 않아도 되는건 덤. 이 실험으로 CNN based 모델보다 더 좋음을 입증할 수 있다고 한다.
Table 5는 Inference Speed에 대한 내용으로, base와 large와는 별로 차이가 없음을, small은 예측 품질에는 큰 차이가 없지만 속도가 2배가 빠름을 어필하며, 산업용 어플리케이션에도 충분히 적용 가능함을 이야기한다. (근데 차이 4%랑, 2~3%면 좀 큰거 아닌가...;;)
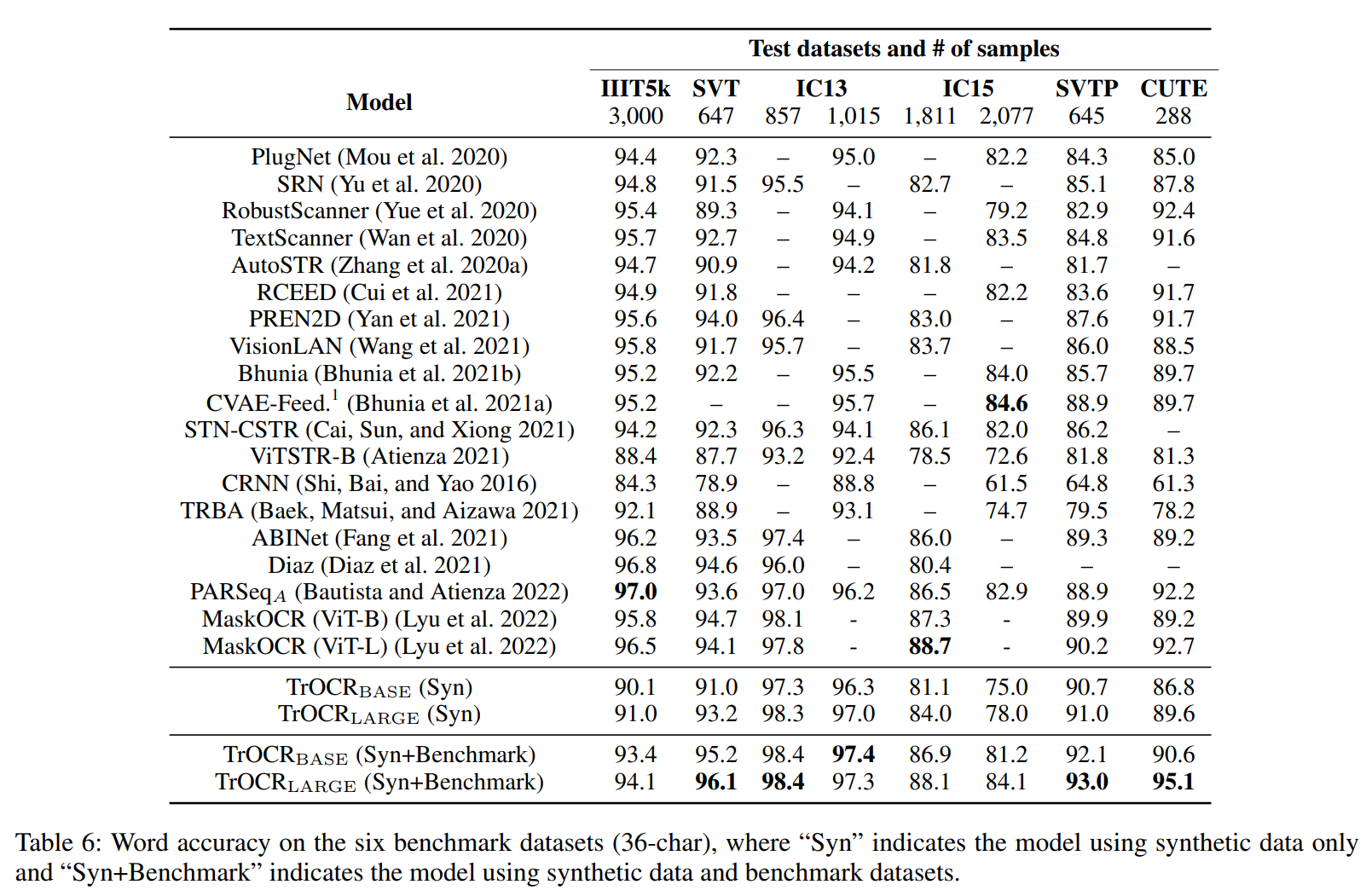
Table 6는 Scene Text Dataset에 대한 설명으로, IIIT5k에서 떨어지는 이유는 이미지에는 특수문자가 있는데 ground truth에는 없는 경우가 있단다... 그리고 기호 처리에 대한 모델 학습도 잘 고려해야 할 것을 강조함.
Related Work
CRNN+CTC -> RNN을 BiLSTM으로 처리 -> seq2seq model -> Transformer based -> Image Transformer를 이야기 하며, Table 6, Table 4에 있는 model 아키텍쳐에 대한 간략한 설명들이 이어진다. (중요한건 TrOCR이 결국 제일 잘된다는 걸테니 그냥 생략하겠다.)
Conclusion
Pre-Training이 가능한 OCR Model에 대해서 알아보았다. CNN에 의지하지 않고도 이미지를 이해할 수 있고, wordpiece 등을 사용하는 Text Decoder를 통해 추가적인 LM이 필요하지 않음을 검증하였다. 실험 결과로 Text Image 모든 분야에서 후처리 없이 가장 잘 되는 모델임을 입증하였다.
개인적으로 SwinV2를 이용해서 Encoder를 학습시키면 Inference속도를 배로 개선할 수 있지 않을까 싶다.
한국어에 대질하기 위해 여러가지 노하우들이 있는데, 업무랑 관련이 있을 수도 있어서, 자세한 이야기는 생략하도록 하겠다.
되게 유용하면서도 읽기 편한 논문이었던듯 하다.




댓글