해당 아티클은,
https://simonjisu.github.io/paper/2018/04/03/nsmcbidreclstmselfattn.html
https://techy8855.tistory.com/8
을 참고하였으며,
https://arxiv.org/pdf/1703.03130.pdf
논문에 기반합니다.
소스코드는,
기본 논문구현은 (GNUv3 라이센스 이므로, 작성된 소스는 해당 라이센스에 기반합니다.),
https://github.com/ExplorerFreda/Structured-Self-Attentive-Sentence-Embedding
시각화는 (MIT 라이센스로, 상위 조건이 더 많은 GNUv3 라이센스를 따라간다고 생각하시면 되겠습니다.),
https://github.com/kaushalshetty/Structured-Self-Attention
를 참고 및 분석, 수정하였습니다.
실무에서, BERT를 사용중인데, 장비의 성능 이슈로 max_seq를 길게 가져갈 수 없는 경우이나, text data가 너무 긴 경우, 분명히 attention에 사용할 부분은 뒤에 걸려있을 수 있을 것 같은데, 어떻게 하여 성능을 쉽게 향상시킬 수 있을지? 에 대한 고민을 하게되었다.
(안은 2가지 정도가 나왔다.)
1안. label text의 char alignment 별로 비교하여, min ~ max의 평균을 잡고, 거기서 iqr 15~25%의 position을 여유로 둬서 문장을 특정 n만큼 최대한 자르는 방법
(label과 비슷한 단어가 빈번하게 등장했던 position 범위는 중요하다고 생각할 수 있지 않을까?)
2안. BERT도 결국 Attention 모델이니, 결국엔 Transformer 기반으로 빠르게 카테고리 분류를 위한 모델을 학습시켜서, Attention Weight를 출력하고, 해당 Attention Weight에서 평균적으로 중요했던 min ~ max 평균만큼 position을 n만큼 최대한 자르는 방법
(모델이 중요도를 학습하게 해서, 그걸 기준 삼아보자?)
1안과 2안을 전부 비교해볼 예정이며, 현재 2안의 BERT 학습 및 테스트 진행중이다.
1안의 경우에는 STT결과를 100% 신뢰할 수 없으므로, alignment가 모호하고, 전체 데이터 셋에서 단어가 제대로 등장하지 않은 set이 더 많은 경우, 이상 결과를 초래할 수 있다.
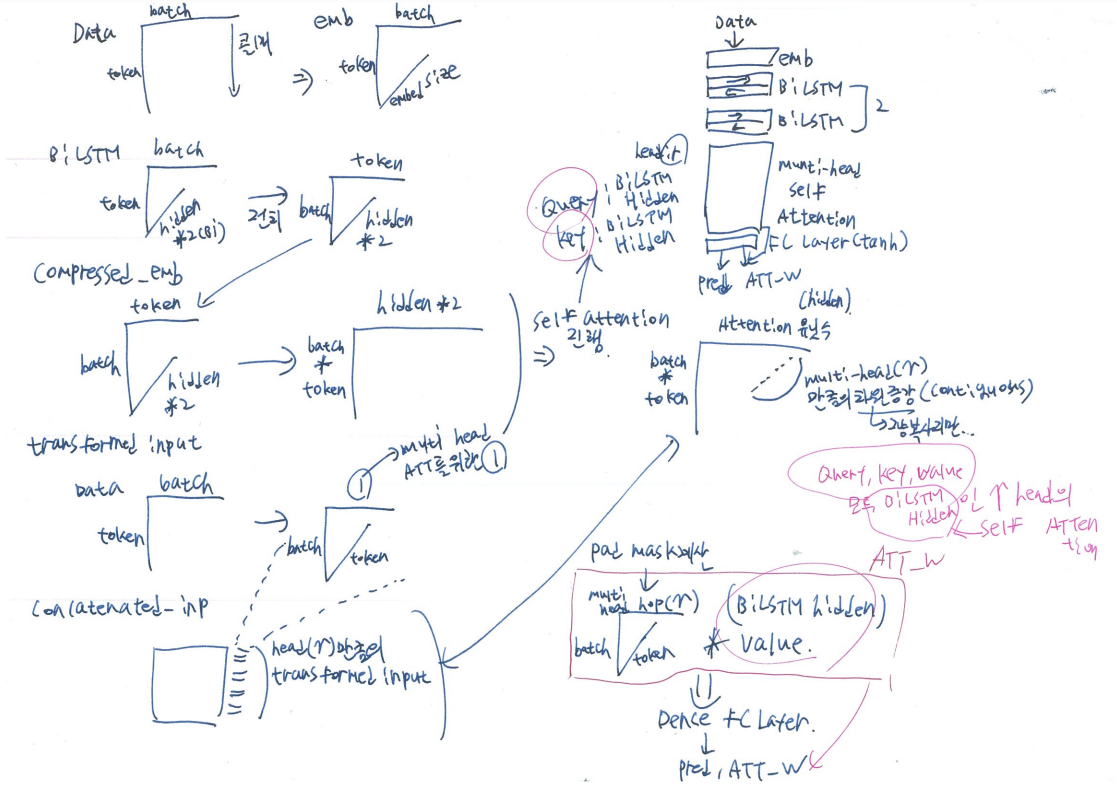
처음에는, 임베딩에 기반한 transformer모델을 바로 구현하여 사용할까 하였는데, 논문을 찾아보다보니,
bi-lstm을 이용해서,

내가 딱 구성하고 싶었던 형태로 레퍼런스가 존재하여, 마침 GIT도 있길래 구현 및 실험해보도록 하였다.
(다만 https://github.com/ExplorerFreda/Structured-Self-Attentive-Sentence-Embedding 해당 GIT에서 바로 pull하면 정상동작하지 않아, model 쪽이나 l2 norm (weight decay)하는쪽을 손봐놓은 소스다.)
수정 완료된 소스 (소스 정리는 차차 하겠습니다.)_
https://github.com/YooSungHyun/deep-learning/tree/master/Structured-Self-Attentive
GitHub - YooSungHyun/deep-learning: 업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자
업무, 스터디간 utils 등 나만의 유용한 소스들을 모아보자. Contribute to YooSungHyun/deep-learning development by creating an account on GitHub.
github.com
논문에 대한 해석은 위에 올려놓은 아티클을 읽어보면 더 상세하게 알 수 있으나, 아주 쉽게 설명해보면,
1. 임베딩을 통해, 단어의 feature를 정의하고
2. bi-lstm을 통해, 단어의 순서간 feature를 정의한 다음,
3. multi-head self-attention으로, 본인 스스로의 단어 순서(문장)에서 중요도를 산정한 다음,
4. 그 해당 중요도로 예측해낸 값과의 실제값을 비교하며, 집중할 문장에서의 중요도를 재산정하고, 단어의 순서와 각단어의 특성을 다시 계산하게 된다.
(마치 사람에게 지문을 읽고, 화자의 의도를 파악해보시오. 라는 문제를 가지고,
어느 지문을 읽고 그렇게 생각했는지를 계속 검수하면서,
문장과 단어의 연관관계를 다시 배워나가는 과정과 비유해볼 수 있겠다.)
그 과정에서 self-attention의 pad mask(패딩을 학습하지 않기 위함)같은 기술적인 부분들이 들어있고,
다만 BERT와 다른점은, 내가 참고한 ExplorerFreda의 소스에는 Softmax의 대상이 무한이 많아질경우 매우 작은 확률값으로도 값이 변할 수 있는 부분에 대한 정규화는 포함되어있지 않다. (간단하게 BERT에서 공식만 가져다가 활용하면 긴 sequence의 문장에서도 더 잘 동작할 수 있을 것으로 판단된다는 것이다.)
또한, weight decay도 디폴트는 0으로 선언되어, 사용되지 않는데, 어짜피 Frobenius Norm이 선언되어있어서, 벡터와 차원행렬의 차이긴 하겠지만, l2 norm이 정상적으로 적용되어있다고 보면 된다. (즉, Adam 파라미터에서 건들지 말 것. 대신 입력 파라미터에 penalization_coeff가 있다.)
self attention의 핵심부분은 아래와 같은데,
해당 소스는 batch_first 기준이 아니기 때문에, data loader 부분부터 전부다 (token,batch,feature)의 형태로 다뤄야된다.
해당 특이사항만 아니라면, 데이터는 전부 잘 내적되는 것을 확인했다.
차근차근 본 부분들을 정리했는데, 이거로 눈에 들어오는 사람이 있으려나...ㅋㅋ;;
3차원에 대한 l2 norm 계산,


정도가 적용되어있고,
visualize 부분은 attention weight를 text token length에 맞춰서, html 파일을 구성하도록 작성되어 있다.
현재 우리 데이터로 적중율은 1200개 데이터 11 카테고리 기준으로 65~70% 성능 정도를 보이며,

분류하고자 하는 카테고리에 맞춰서 어텐션이 잘 되는 것을 볼 수 있다.
아마 BERT로 적당히 잘라서 분류해봤을때 잘 안된다면, 그냥 이 모델을 사용할 수도 있겠고,
BERT로 더 잘 된다면, 1안과 2안을 비교해볼 예정이다.
그리고 BERT 2안으로 만약 잘 된다면, 실제로 어떤 이유에서 그렇게 분류되었는지 등을 설명하는 데에도 활용할 예정이다.
'논문으로 현업 씹어먹기' 카테고리의 다른 글
| 최신 AI Trend - Google의 Pathways (2 - Paper 리뷰) (0) | 2022.04.13 |
|---|---|
| 최신 AI Trend - Google의 Pathways (1 - 역사와 톺아보기) (0) | 2022.04.11 |
| Time Forecasting에 있어 느낀, Attention의 한계 (8) | 2021.05.25 |
| 응~ 역전파 이해해야되~ - (Yes you should understand backprop / Andrej Karpathy) (0) | 2021.05.07 |
| 딥러닝을 대하는 우리의 자세 - (A Recipe for Training Neural Networks / Andrej Karpathy) (3) | 2021.04.22 |


댓글